


1 引言
贫困和收入不均等以及其他与收入分配相关的议题长期受到国内外政府、社会和学术界的广泛关注. 在国际上, 减贫和缩小贫富差距是由193个国家元首签署、联合国发起和推进的可持续发展目标(SGDs)的核心. 在亚洲, 众多国家包括印度和印度尼西亚等都把反贫困和包容性增长作为重大战略部署. 中国政府更是先后提出了和谐社会、精准扶贫、共同富裕等理念并付诸实践, 创造了人类发展史上的减贫神话(汪晨等(2020)).
显而易见, 不均等和贫困等指标的度量极为重要, 否则将无法监测贫困或收入差距的趋势, 难以科学地制定相关政策, 更不可能开展与收入分配相关(包括政策评估)的研究. 所以, 世界银行建立了知名的Povcal网站, 专门提供国家层面的贫困估算值1; 联合国发展经济学研究院不断更新世界各国的收入不均等指标2; 世界财富与收入数据库(WID.world)也在持续公布国家内与国家间收入与财富分布历史变化数据3. 这些宝贵的数据被大量运用于不同的场合和研究中. 但是, 现有数据库基本上只能提供国家层面的时间序列, 次国家(sub-national)层面的相关指标往往缺失. 这就是为什么在实证模型中直接加入贫困或不均等变量的学术成果相对较少(跨国回归除外). 特别地, 贫困和收入不均等问题在中国的重要性不言而喻, 但鲜有文献在模型中聚焦或控制这些变量, 尽管它们影响诸多经济社会变量, 如增长、消费、投资、教育、健康和犯罪等等.
1https://povertydata.worldbank.org/poverty/home/
2https://www.wider.unu.edu/database/world-income-inequality-database-wiid.
3https://wid.world/data/.
面对与收入分配相关的指标的缺失, 大部分研究都选择直接放弃使用相关变量, 另有部分研究则尝试使用城乡收入差距作为总体收入差距的代理变量(陆铭等(2005), 陈春良和易君健(2009)). 然而, 任何一个国家或地区的收入差距都包括三大成分: 城乡收入差距、城市内部收入差距和农村内部收入差距, 因此使用城乡收入差距作为代理变量会带来一定的误差. 当然, 随着微观调查数据如中国家庭追踪调查(CFPS)/中国综合社会调查(CGSS)/中国家庭金融调查(CHFS)等的出现, 学者们可以估算省级层面的贫困和不均等指标. 但这些微观数据库涵盖的年份有限, 部分样本的代表性也受到质疑.
幸运的是, 早在1970年代, 经济学界就提出了基于分组数据还原个体观察值的方法(如Gastwirth (1972), Kakwani and Podder (1973)), 而且我国国家和部分省市统计局在其统计年鉴上常常公布收入分组数据. Shorrocks and Wan (2009)在前人研究的基础上提出了迭代法, 使得还原的数据更为准确. 但是, 现有的方法均未考虑数据截断的问题. 此外, 将分组数据还原为个体观察值都需要假设具体的统计分布函数. 为此, Shorrocks and Wan (2009)进行了有限的蒙特卡罗实验, 试图评估不同假设的可靠性. 然而, 他们只考虑了三种不同的分布函数, 忽略了其他可能更为可靠的、用以刻画收入分布的函数(如Singh and Maddala (1976), Dagum (1977), McDonald and Xu (1995)).
特别重要的是, 国内外微观调查数据都面临相关变量分布底端和顶端观察值缺失, 尤其是高收入家户抽样不足的问题(王小鲁(2007)), 导致相关研究的可靠性被削弱. 举例来说, 低收入群体数据的缺失将导致贫困率的低估, 高收入群体数据的缺失将导致不均等的低估. 鉴于此, 中国家庭金融调查(CHFS)适当增加了富裕地区和富裕家庭的抽样比重, 但针对CHFS的可靠性仍然存在争议4. 此外, 也有学者尝试使用税务数据(Piketty (2003))或富豪榜数据进行弥补(李实和罗楚亮(2011), 罗楚亮(2019)). 但这些数据与微观调查数据之间缺乏一致性.
4出自甘犁2013年《以公开科学的抽样调查揭示真实的中国》, 是基于李实和岳希明质疑CHFS而发表的《我们更应该相信谁的基尼系数》的回应. 甘文链接: http://www.ciidbnu.org/news/201302/20130223120202706.html. 李和岳文链接: http://www.ciidbnu.org/news/201301/20130123092800706.html.
基于2018年CFPS数据进行蒙特卡罗实验, 本文旨在评估并改进Shorrocks and Wan (2009)提出的基于分组数据的还原方法. 具体而言, 本文首先在Shorrocks and Wan (2009)的基础上考虑了更多的分布函数形式, 评估比较了八种常用的收入分布函数所"还原"的数据的精确度和可靠性. 结果发现, Dagum分布在大多数情况下都有较好的表现. 本文同时评估了Shorrocks and Wan (2009)的迭代调整法的实际效果, 发现该方法在不同状况下都有助于提高"还原"数据的可靠性. 接着, 本文首次引入条件分布法来解决分组数据截断问题, 将无条件分布扩展为双边截断的条件分布来对数据进行"还原", 并评估了其效果. 结果同样表明, Dagum分布能够有效处理顶端和底端收入数据缺失问题.
本文的发现表明, 学术界可以结合使用本文提出的条件分布法和Shorrocks and Wan (2009)的数据还原法, 基于Dagum分布对分组数据进行还原, 从而计算国家或次国家层面的收入不均等、贫困和中等收入群体占比等等指标. 特别需要说明的是, 本文为中国省际贫困与不均等指标的测算提供了重要的方法支持, 这一贡献与张军等(2004)以及郑世林和杨梦俊(2020)类似, 前者将永续盘存法应用于中国早期资本存量的测算, 后者估算了中国无形资本存量.
论文余下的内容安排如下: 第二部分梳理与分组数据处理及数据缺失问题相关的文献; 第三部分讨论分组数据"还原"问题, 并基于蒙特卡罗实验评估八种常见的收入分布函数的还原效果; 第四部分提出条件分布法, 以"还原"两端缺失的数据, 并评估各分布函数的表现; 第五部分结合使用条件分布法和Shorrocks and Wan (2009)的框架, 估算中国历年的基尼系数和中等收入群体占比指标; 第六部分为小结.
2 文献回顾
2.1 收入分组数据的应用
早在20世纪70年代, 基于分组数据测算收入分配指标的研究就开始大量出现(如Gastwirth (1972), Kakwani and Podder (1973), Kakwani (1976)), 相关收入分布函数的设定也随之得到关注(Singh and Maddala (1976), Dagum (1977), McDonald and Xu (1995)). 这些较早的研究大多在参数拟合之后直接生成模拟样本, 而不对还原数据进行调整. Shorrocks and Wan (2009)提出了迭代法, 即根据各组的均值对模拟样本进行迭代法调整, 降低了还原数据与真实数据之间的偏差.
国内也有学者基于收入分组数据, 估算中国的收入分配指标. 如胡志军等(2011)在对数正态分布、威布尔分布和广义贝塔II型(GB2)分布的假设下, 对中国农村和城市居民的收入分组数据进行拟合并据此计算基尼系数. 基于极大似然估计值和各收入区间的人口份额拟合值与样本值的偏差, 胡志军等(2011)发现GB2表现较好, 该发现得到张萌旭等(2013)的证实. 陈建东等(2013)比较了不同分布函数的拟合效果, 发现对数逻辑斯蒂分布占优. 遗憾的是, 现有文献大多没有考虑Shorrocks and Wan (2009)的迭代法, 也没有关注基尼系数之外的其他收入分配指标(祁磊和艾小青(2021)), 更没有考虑数据缺失或截断问题(见下一小节).
2.2 数据缺失问题
影响微观调查数据质量的主要因素有两个: 一是样本代表性; 二是调查个体回复率. 在现实中, 通常会有一定比例的个体拒绝参与调查或者不在家, 导致回复率不足. 该问题又与收入水平相关: 高收入群体所占比例低, 其居住环境更具封闭性, 不容易被抽取; 即便被抽中, 出于隐私或安全考虑, 他们有动机隐瞒真实收入水平或者直接拒绝接受调查(no-response) (Korinek et al.(2006, 2007), Sabelhaus et al. (2012), Burkhauser et al. (2011)). Deaton (2005)发现通过家户调查得出的人均消费远低于国家统计数据, 这在欠发达国家中更加明显, 包括印度(Banerjee and Piketty (2005))和中国(王小鲁(2007)). 低收入群体因无家可归等现象也存在抽样不足或回复率偏低的问题. 这些问题显然会给统计或计量估算带来偏误. 罗楚亮(2019)就发现, 基于住户调查数据所得的基尼系数都存在低估.
为了解决收入数据缺失问题, 王小鲁(2010)使用了社会学中的"滚雪球法", 通过调查亲戚朋友等熟人进行核对调整, 以改善高收入样本的数据真实性. 但王有捐(2010)指出, "滚雪球法"在调查城市和调查样本的选择等方面存在主观性. 李实和罗楚亮(2011), 罗楚亮(2019)使用财富榜和高管薪酬数据弥补高收入样本的缺失. 白重恩等(2015)基于个体消费数据推算了我国居民的隐性收入, 发现不考虑隐性收入使得基尼系数明显低估. 这些尝试都借助于外部数据, 但外部数据的获取和匹配不但存在困难, 而且外部数据与微观调查数据之间一般不具有一致性.
3 分组数据还原
3.1 分组数据还原方法
Shorrocks and Wan (2009)构造了一种将分组数据"还原"为个体观察值的方法, 该方法在某一统计分布(如对数正态分布) 的假设下, 首先用分组数据估算该分布的参数(分布的期望值可以设为1), 并在此基础上产生洛伦兹曲线上的个体观测值. 然后对每组观测值进行调整, 以保证"还原"的数据的平均值与实际观察到的各组平均值相等, 同时保证整个洛伦兹曲线是平滑和单调上升的. 具体地, 将收入分组数据记为从低到高的1到
现在, 依据(2)式得到
其中
最后是分两步调整这些观测值. 首先, 利用(3)和(4)式使得观察到的、真实的组收入均值
然后, 利用(5)和(6) 式将每组的均值
其中,
这些调整过的观测值即可用来估算各种收入分配指标.
但收入变量不一定服从对数正态分布. 本文将评估常见的8种分布函数的"还原"的可靠性和精确度, 其中包括具有两参数的对数正态分布(Lognormal)、Gamma分布(Gamma)、Weibull分布(Weibull)和Pareto分布(Pareto); 也包括具有三参数的Singh-Maddala分布(SM)、Dagum分布(Dagum)和Beta2型分布(Beta2); 最后还包括具有四参数的Generalized Beta Distribution of the Second Kind (GB2)5. 其相应的概率密度函数及基尼系数计算公式如表 1所示.
5关于Lognormal分布函数参见Smith and Merceret (2000); 关于Gamma分布函数见Salem and Mount (1974); 关于Weibull分布函数见Menon (1963); 关于SM分布函数见Singh and Maddala (1976); Beta2分布函数见Slottje (1984); 关于Dagum分布函数见Dagum (1977); 关于GB2分布函数见McDonald (1984); 关于Pareto分布函数的相关信息可参考Krishnaji (1970).
表1 不同分布概率密度函数和基尼系数
| 分布类型 | 概率密度函数 | 基尼系数 |
| Lognormal | ||
| Gamma | ||
| Weibull | ||
| SM | ||
| Beta2 | ||
| Dagum | ||
| GB2 | ||
| Pareto |
在表 1中,
3.2 蒙特卡罗设计
基于表 1和收入分组数据, 可估算不同分布的参数, 然后生成包含任意个观测值的收入样本. 具体方法如下:
首先, 从CFPS原始样本中随机抽取样本体积为
重复以上过程
3.3 还原效果评估
参考Shorrocks and Wan (2009)的做法, 本文采用数值和指标比较两种方法对"还原"效果进行评估.
数值比较的具体方法为, 将真实收入数据与还原的收入数据分别从小到大排列, 计算洛伦兹曲线上每个个体所对应的收入份额偏差, 再对这一偏差取绝对值, 然后进行加总得出加总偏差6, 最后计算出
6由于观察结果以收入份额表示, 平均绝对百分比偏差的值与样本量
其中
其中, 上标Actual和Simulate分别表示真实数据和还原出的数据. 本文中的分位加总在十分位内进行. 比如, 当
最后, 我们计算多次模拟下的平均总和偏差:
指标比较方面, 本文考虑收入不均、等贫困发生率和中等收入群体占比三个指标的精确度:
1) 本文采用最常用的度量不均等的指标——基尼系数(Gini).
2) 贫困发生率. 本文采用三条贫困线估算贫困发生率. Poverty2300代表基于中国官方贫困线(以2010年价格计算的、每人每年2300元)计算的贫困发生率. Poverty19和Poverty32分别为世界银行2011年确定的国际极度贫困标准(1.9美元/人/天)和国际贫困标准(3.2美元/人/天)下的贫困发生率.
3) 中等收入群体占比. 中等收入群体的界定可以使用绝对标准或相对标准. 绝对标准方面, 本文根据国家统计局的"以中国典型的三口之家年收入在10万元
7见国家统计局局长就2018年国民经济运行情况答记者问, 网址: http://www.stats.gov.cn/tjsj/sjjd/201901/t20190121_1645944.html.
使用指标法进行评估, 可以计算多次模拟下的平均绝对百分比误差(mean absolute percentage error, MAPE), 其计算公式如下:
其中
4 评估结果
4.1 不同分布假设下的还原效果比较
本文首先使用前文提出的方法基于分组数据获得了还原样本, 然后将其与真实样本进行分段比较, 考察每十分位所对应的收入份额的绝对偏差之和, 结果如图 1所示. 图中可以看出还原样本的收入份额绝对偏差大致随着分位的增大而增加. 不管基于何种分布, 还原样本在第1至第8分位内的偏差都较小, 而第9和第10分位内的偏差则明显较大. 总体来说, Dagum分布表现最优, 而Pareto分布、Gamma分布和Weibull分布的整体还原效果欠佳, 无论是在低分位还是高分位上偏差都明显高于其他分布. 在第1至第8分位内Lognormal、Dagum、SM、Beta2、GB2分布的偏差相差很小且都处于较低水平, 而在第9和第10分位内, 不管是五等份分组还是十等份分组数据, 采用Dagum分布所得还原样本的偏差都是最小的, 第10分位内的个人收入份额的绝对偏差小于4个百分点, 总体收入份额的绝对偏差之和也在5个百分点以内.
图1
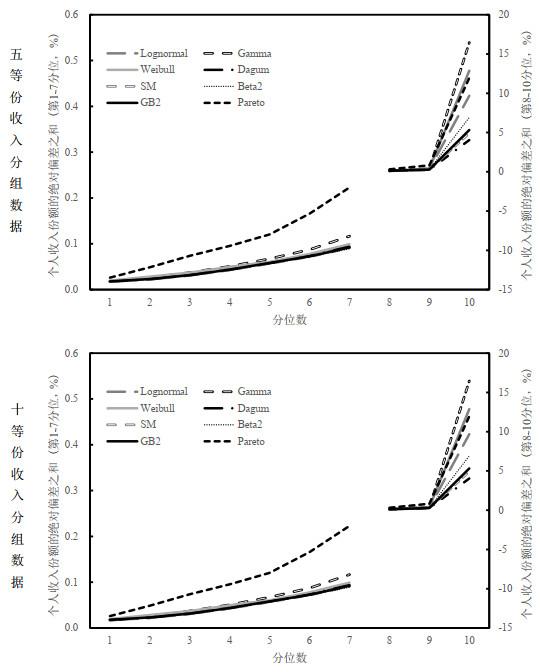
具体而言, 当收入数据为五等份分组形式时, 基于Dagum分布"还原"出的样本在第9分位内的收入份额的绝对偏差之和仅为0.32个百分点, SM分布和GB2分布的结果次之, 分别为0.47和0.51个百分点, 而Gamma、Weibull和Pareto分布的相应偏差都超过了3个百分点. 第10分位内收入份额的绝对偏差之和的对比更加明显, Dagum分布的偏差低至5.14个百分点, 而Gamma、Weibull和Pareto分布的偏差都在13个百分点以上. 如果计算总体收入份额的绝对偏差之和, 会发现表现较好的依然是Dagum、SM和GB2分布, 其对应的结果分别为4.97、6.10、6.30个百分点. 而当收入数据为十等份分组时, Dagum、SM和GB2分布的收入份额的绝对偏差之和分别为4.76、5.64、6.06个百分点, 总体偏差相较于五等份分组的情况都有一定程度的降低, 但各分布偏差大小的排序均未发生改变.
图 2绘制了基于Dagum分布进行的单次模拟中"还原"的洛伦兹曲线与真实洛伦兹曲线之间的相对偏差. 其中"调整后"表示的是经过迭代法调整后的样本, "调整前"表示未经迭代的样本, 可以看出迭代法调整后总体偏差情况有所改善.
图2
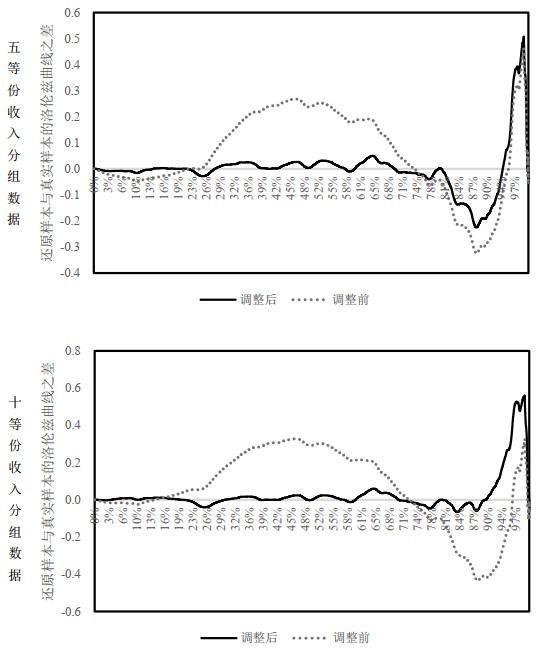
图3
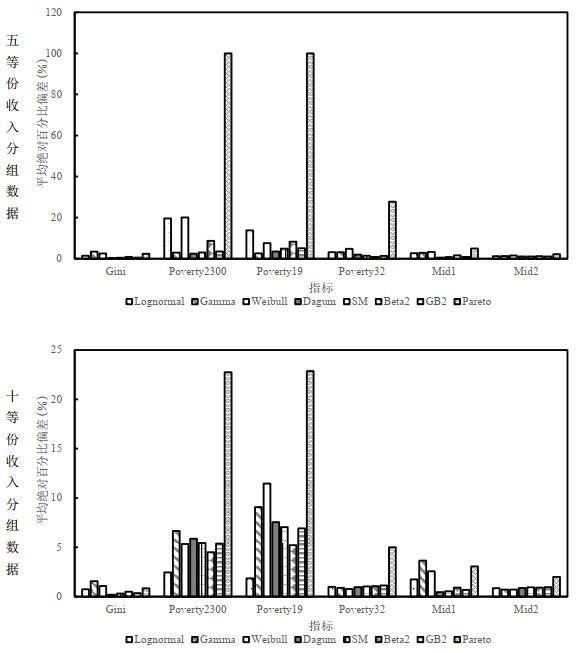
从贫困发生率的偏差来看, 在不同的分组数据、不同贫困标准下, 各分布的平均偏差表现有所不同. 在五等份分组数据中, Gamma、Dagum、SM和GB2分布表现较好, 而对于十等份分组数据来说, Lognormal分布有较为明显的优势. 考虑到十等份分组数据下各分布结果的偏差都偏小, 此处更加关注五等份分组数据的评估结果. 具体到各个贫困发生率的指标上, 在五等份分组数据下, 当以Poverty2300的平均绝对百分比偏差为标准时, Dagum分布的表现最好, 偏差为2.49%, Gamma分布和SM分布的偏差也较低, 分别为2.94%和3.02%; 以Poverty19的平均绝对百分比偏差为标准时, 表现最好的为Gamma分布, 偏差为2.65%, Dagum分布则以3.53%的偏差略次于Gamma分布; 而以Poverty32为标准时, 情况再次发生变化, Beta2分布的偏差变得最小, 仅为0.89%, 明显低于Dagum分布和Gamma分布的偏差. 不论使用哪一个贫困线下的贫困发生率作为评估标准, Pareto分布的平均绝对百分比偏差都是100%, 这是因为Pareto分布对于低收入部分的数据拟合效果较差, 导致通过模拟样本计算出的贫困率为0. 需要说明的是, 由于本文所选取的样本中贫困发生率较低, 因此图中所展示的平均绝对百分比偏差在数值上会比较大, 但其所对应的绝对偏差大多不到一个百分点.
从中等收入群体占比的偏差出发, 依然可以得出Dagum分布的表现较优这一结论. 采用Mid1指标时, Dagum分布的平均绝对百分比偏差是最小的, 五等份分组与十等份分组数据下偏差分别为0.52%和0.46%. 采用Mid2指标时, 除Pareto分布的偏差较大以外, 其他分布的表现都比较接近.
整体来看Dagum分布、SM分布、Beta2分布和GB2分布的差别不大, 且在各评估指标下都有较好的表现, 其中Dagum分布的综合表现最优.
4.2 迭代法的效果评估
表 2上半部分展示了使用迭代法与否所获得的收入份额的绝对偏差之和的均值. 以基于五等份分组数据、重复模拟100次的情况为例, 基于Dagum分布的参数估计生成的样本与真实样本相比, 收入份额的平均绝对偏差之和为5.21个百分点, 而在进行了迭代法调整之后, 这一偏差降低到4.97个百分点. 在十等份分组数据的情况下, 迭代法调整前后的偏差分别为5.23和4.76个百分点. 可以看出, 迭代法整体上可以缩小偏差, 且这一效应在Gamma分布、Weibull分布、Pareto分布的假设下最为明显, 这可能跟这三种分布的直接拟合结果较差有关. 而在Lognormal、Dagum、SM、Beta2、GB2这五种分布下, 迭代法的优势不太明显, 但除五等份分组数据下的GB2略微增大了偏差外, 其余情况下迭代法都能够在一定程度上改善还原样本的表现.
表2 不同模拟次数下迭代法调整前后偏差情况(单位: %)
| 指标 | 分组数 | 模拟次数 | 是否调整 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| 个人收入份额 | 五等份分组 | 100 | 调整后 | 11.89 | 20.81 | 17.53 | 4.97 | 6.10 | 8.56 | 6.30 | 19.49 |
| 调整前 | 12.69 | 26.42 | 32.51 | 5.21 | 6.11 | 8.77 | 6.28 | 37.49 | |||
| 200 | 调整后 | 11.90 | 20.78 | 17.49 | 5.02 | 6.15 | 8.60 | 6.50 | 19.47 | ||
| 调整前 | 12.69 | 26.33 | 32.61 | 5.27 | 6.17 | 8.80 | 6.68 | 37.51 | |||
| 十等份分组 | 100 | 调整后 | 10.49 | 17.39 | 13.77 | 4.76 | 5.64 | 7.66 | 6.06 | 13.85 | |
| 调整前 | 12.87 | 27.51 | 29.13 | 5.23 | 5.89 | 8.66 | 6.85 | 41.55 | |||
| 200 | 调整后 | 10.50 | 17.38 | 13.76 | 4.82 | 5.70 | 7.69 | 5.97 | 13.66 | ||
| 调整前 | 12.87 | 27.41 | 29.14 | 5.30 | 5.95 | 8.69 | 6.49 | 40.84 | |||
| 基尼系数 | 五等份分组 | 100 | 调整后 | 1.41 | 3.46 | 2.56 | 0.23 | 0.47 | 0.90 | 0.52 | 2.40 |
| 调整前 | 1.14 | 15.08 | 20.46 | 0.49 | 0.70 | 0.95 | 0.72 | 9.98 | |||
| 200 | 调整后 | 1.40 | 3.45 | 2.55 | 0.22 | 0.48 | 0.90 | 0.55 | 2.40 | ||
| 调整前 | 1.13 | 15.04 | 20.67 | 0.49 | 0.70 | 0.95 | 1.11 | 9.99 | |||
| 十等份分组 | 100 | 调整后 | 0.75 | 1.56 | 1.07 | 0.20 | 0.31 | 0.50 | 0.36 | 0.84 | |
| 调整前 | 0.86 | 17.89 | 15.47 | 0.43 | 0.53 | 0.54 | 1.52 | 13.34 | |||
| 200 | 调整后 | 0.75 | 1.56 | 1.07 | 0.20 | 0.31 | 0.51 | 0.34 | 0.82 | ||
| 调整前 | 0.85 | 17.85 | 15.56 | 0.43 | 0.53 | 0.54 | 1.02 | 13.00 |
表 2下半部分展示了不同模拟次数下基尼系数的平均绝对百分比偏差, 同样发现绝大多数情况下迭代法可以明显降低还原样本的偏差. 即使是对于Dagum、SM、GB2分布这样直接拟合效果就已经较好的分布函数, 使用迭代法调整后基尼系数的平均百分比偏差依然降低了0.2个百分点以上.
对比五等份分组与十等份分组的评估结果还可以发现, 十等份分组数据的偏差大多都小于五等份分组数据. 这与直觉相符, 即分组越细, 分组数据能够提供的信息越多, 还原样本与真实样本的偏差就越小.
此外, 前文展示的是100次模拟的结果. 表 2报告了200次模拟与100次模拟结果的对比, 可以看到二者十分接近. 以基于Dagum分布还原五等份分组数据并进行迭代法调整后的结果为例, 100次模拟下个人收入份额的平均绝对偏差之和为4.97个百分点, 而200次模拟下的对应偏差之和为5.02个百分点, 二者相差0.05个百分点. 如果关注于基尼系数的平均百分比偏差, 100次模拟与200次模拟的结果分别为0.23%和0.22%, 仅相差0.01个百分点. 这表明模拟次数达到100时还原偏差已经基本稳定在某一水平. 附录中表A3至表A18详细展示了在不同模拟次数下、迭代法前后的各分位内收入份额的平均绝对偏差和各个指标的平均绝对百分比偏差, 从中也能得到与前文分析一致的结果.
4.3 截断分组数据还原
为弥补数据缺失, 本文引入条件分布法来进行拟合. 具体来说, 设
根据数据缺失部位的不同, 可以分成以下三种情况:
1) 高位数据缺失
当仅考虑高收入数据缺失时, 实际观察到的样本中有最大点
(13) 式的含义为, 可观测的收入分布(低于
2) 低位数据缺失
当仅考虑低位数据缺失时, 实际观察到的样本由中有最小点
实际观察到的样本占总样本比例为
3) 高低位都存在缺失
当高低位数据都存在缺失时, 实际观察到的样本有最小点
实际观察到的样本占总样本比例为
以上各式中,
具体地说, 假设已知数据高低两端的缺失比例分别为
条件分布拟合相比于无条件分布拟合增加了两个待估参数
4.4 还原效果评估
同样基于CFPS2018的数据进行蒙特卡罗评估, 但此处要先对样本做不同程度的双边截断处理8, 其中截断比例分别设置为0.5%、1%、1.5%、2%、2.5%、3%. 假设两端的截断比例a%未知, 通过前述方法对数据进行还原, 再将还原样本与真实样本进行比较, 评估各分布在此方法下的表现. 根据前面的结果, Pareto分布和Weibull分布的还原表现较差, 故这里不再展示相应结果.
8现实中调查数据通常同时存在高低端的缺失, 但两端的缺失比例不一定相同, 为节省篇幅此处仅讨论了双边缺失相同比例的情况.
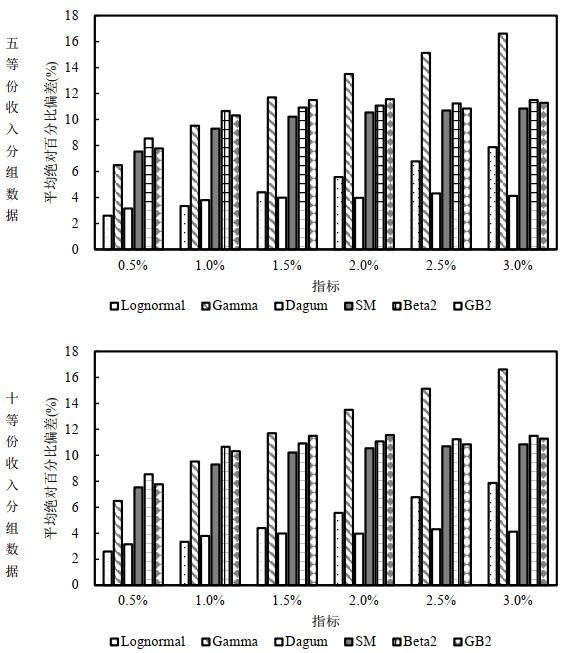
图 4展示了不同截断比例下, 不同分布函数的还原表现. 当数据为五等份分组数据时, 不论缺失比例为多少, Dagum分布的偏差都最小, 绝对偏差之和介于8
图4
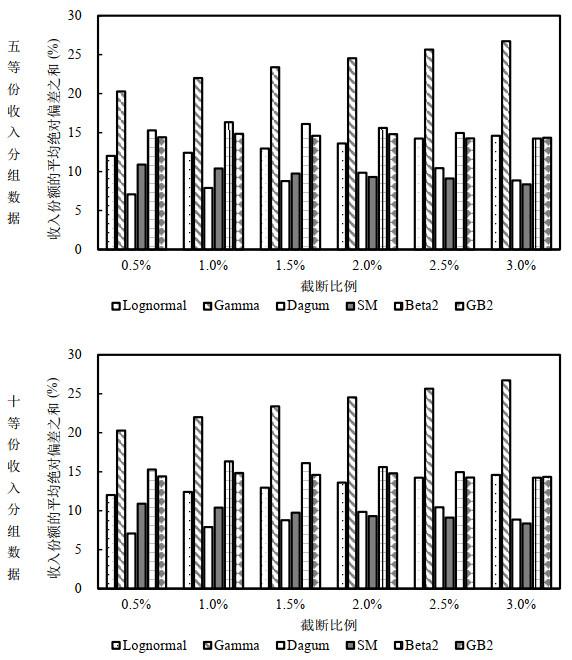
图5
9本文中贫困发生率和中等收入群体的指标使用了多个标准, 由于篇幅限制将对比结果在附录中展示.
综合本部分的所有评估结果, 可以发现Dagum分布的总体表现是最好的, 不论怎么评估, 它都具有较小的偏差, 在收入份额占比和基尼系数的还原上具有明显的优势. SM分布总体上略逊于Dagum分布, 但同样有着不错的表现. 而其他分布则总在某些情况下偏差较大, 可能在实际应用中带来较大的误差.
表 3展示了不同情况下收入份额的平均绝对偏差之和. 可以看到, 如果数据存在截断, 但在拟合时不予考虑, 将会造成相当大的偏差. 且截断比例越大, 这一偏差越大. 如果考虑到截断问题, 使用条件分布进行拟合, 还原结果在多数情况下都有明显改善. 在此基础上再应用Shorrocks and Wan (2009)的迭代法, 偏差将进一步降低. 以截断比例为1%的五等份分组数据为例, 不考虑截断时, 收入份额的平均绝对偏差之和为15.35个百分点, 考虑截断后偏差降低到8.46个百分点, 使用迭代法进行调整后偏差进一步降为8.37个百分点. 除了偏差较小之外, 引入条件分布的还原方法还有一个明显的优点——随着截断比例的变化, 偏差的幅度能够保持相对稳定, 而不会出现因截断比例的增加导致偏差大幅升高的情况.
表3 不同模拟次数下迭代法调整前后个人收入份额的平均绝对偏差之和(单位: %)
| 分组数 | 处理方法 | 截断比例 | Lognormal | Gamma | Dagum | SM | Beta2 | GB2 |
| 五等份分组 | 考虑截断且进行调整 | 0.50% | 12.49 | 22.29 | 8.02 | 14.65 | 16.19 | 14.93 |
| 1.00% | 12.69 | 23.28 | 8.37 | 16.74 | 17.88 | 17.56 | ||
| 1.50% | 13.03 | 24.13 | 8.43 | 17.73 | 18.03 | 18.81 | ||
| 2.00% | 13.53 | 24.91 | 8.22 | 17.93 | 18.06 | 18.71 | ||
| 2.50% | 14.12 | 25.66 | 8.52 | 17.92 | 18.11 | 17.76 | ||
| 3.00% | 14.70 | 26.42 | 8.07 | 17.92 | 18.28 | 18.16 | ||
| 考虑截断但未进行调整 | 0.50% | 12.82 | 25.34 | 8.11 | 14.69 | 16.33 | 14.99 | |
| 1.00% | 12.91 | 25.65 | 8.46 | 16.76 | 17.88 | 17.56 | ||
| 1.50% | 13.18 | 26.03 | 8.54 | 17.74 | 18.03 | 18.80 | ||
| 2.00% | 13.64 | 26.46 | 8.34 | 17.93 | 18.05 | 18.70 | ||
| 2.50% | 14.20 | 26.94 | 8.67 | 17.91 | 18.09 | 17.74 | ||
| 3.00% | 14.75 | 27.45 | 8.23 | 17.90 | 18.25 | 18.12 | ||
| 未考虑截断 | 0.50% | 15.47 | 22.99 | 11.78 | 13.96 | 15.80 | 16.11 | |
| 1.00% | 17.76 | 24.44 | 15.35 | 17.40 | 18.91 | 19.77 | ||
| 1.50% | 19.55 | 25.52 | 17.85 | 19.67 | 20.97 | 21.86 | ||
| 2.00% | 21.12 | 26.44 | 19.86 | 21.45 | 22.59 | 23.38 | ||
| 2.50% | 22.60 | 27.33 | 21.63 | 23.04 | 24.04 | 24.71 | ||
| 3.00% | 23.99 | 28.19 | 23.20 | 24.46 | 25.34 | 25.97 | ||
| 十等份分组 | 考虑截断且进行调整 | 0.50% | 12.00 | 20.29 | 7.09 | 10.91 | 15.28 | 14.41 |
| 1.00% | 12.41 | 22.01 | 7.90 | 10.39 | 16.33 | 14.85 | ||
| 1.50% | 12.95 | 23.38 | 8.79 | 9.74 | 16.11 | 14.59 | ||
| 2.00% | 13.60 | 24.55 | 9.84 | 9.31 | 15.60 | 14.81 | ||
| 2.50% | 14.24 | 25.65 | 10.44 | 9.11 | 14.95 | 14.26 | ||
| 3.00% | 14.60 | 26.72 | 8.87 | 8.36 | 14.23 | 14.35 | ||
| 考虑截断但未进行调整 | 0.50% | 12.89 | 25.37 | 7.13 | 10.92 | 15.32 | 14.44 | |
| 1.00% | 13.05 | 25.66 | 7.92 | 10.41 | 16.30 | 14.83 | ||
| 1.50% | 13.39 | 26.04 | 8.78 | 9.77 | 16.08 | 14.57 | ||
| 2.00% | 13.92 | 26.48 | 9.82 | 9.33 | 15.57 | 14.79 | ||
| 2.50% | 14.46 | 26.97 | 10.45 | 9.14 | 14.92 | 14.24 | ||
| 3.00% | 14.77 | 27.50 | 9.11 | 8.43 | 14.20 | 14.32 | ||
| 未考虑截断 | 0.50% | 16.01 | 20.59 | 13.85 | 14.86 | 15.92 | 16.31 | |
| 1.00% | 19.53 | 22.76 | 18.30 | 19.03 | 19.68 | 20.40 | ||
| 1.50% | 22.05 | 24.37 | 21.25 | 21.76 | 22.20 | 22.70 | ||
| 2.00% | 23.94 | 25.70 | 23.48 | 23.87 | 24.18 | 24.49 | ||
| 2.50% | 25.70 | 26.96 | 25.40 | 25.70 | 25.92 | 26.15 | ||
| 3.00% | 27.22 | 28.15 | 27.02 | 27.26 | 27.43 | 27.56 |
与本部分第二小节类似, 此处把模拟次数由100次增加到200次, 并观察还原结果是否存在显著差异. 表 4展示了200次模拟下, 依照条件分布法拟合并进行迭代法调整所得到的个人收入份额的平均绝对偏差之和, 结果依然与100次模拟的情况接近.
表4 200次模拟下个人收入份额的平均绝对偏差之和(单位: align="left")
| 分组数 | 截断比例 | Lognormal | Gamma | Dagum | SM | Beta2 | GB2 |
| 五等份分组 | 0.5 | 12.51 | 22.25 | 7.99 | 14.55 | 16.15 | 14.90 |
| 1.0 | 12.71 | 23.23 | 8.56 | 16.53 | 17.70 | 17.39 | |
| 1.5 | 13.04 | 24.08 | 8.46 | 17.55 | 17.83 | 18.58 | |
| 2.0 | 13.53 | 24.85 | 8.46 | 17.69 | 17.83 | 18.42 | |
| 2.5 | 14.10 | 25.59 | 8.58 | 17.63 | 17.90 | 17.47 | |
| 3.0 | 14.64 | 26.35 | 8.08 | 17.60 | 18.11 | 17.74 | |
| 十等份分组 | 0.5 | 12.00 | 20.27 | 7.08 | 10.84 | 15.27 | 14.63 |
| 1.0 | 12.41 | 21.98 | 8.00 | 10.28 | 16.22 | 14.82 | |
| 1.5 | 12.94 | 23.34 | 8.97 | 9.69 | 15.98 | 14.60 | |
| 2.0 | 13.59 | 24.50 | 10.02 | 9.31 | 15.48 | 14.76 | |
| 2.5 | 14.21 | 25.60 | 10.46 | 9.07 | 14.77 | 14.27 | |
| 3.0 | 14.54 | 26.66 | 8.86 | 8.21 | 14.05 | 14.24 |
5 方法应用
图 6展示了采用Dagum分布还原全国居民收入分组数据计算出的基尼系数, 可以看出考虑截断的基尼系数估算值比不考虑截断的估计值要高, 但二者趋势相似. 图中居民收入基尼系数的变化可以划分为三阶段, 其中2013–2015年基尼系数明显下降, 2015–2018年开始提升, 之后又呈缓慢下降趋势. 这与城乡收入倍差的降幅在趋势上基本一致. 城乡收入差距是总体收入差距的重要组成部分(Wan (2007)), 2013年至今城乡收入倍差连年下降, 较高降幅与收入差距缩小的对应在一定程度上体现了基尼系数测算结果的可靠性.
图6
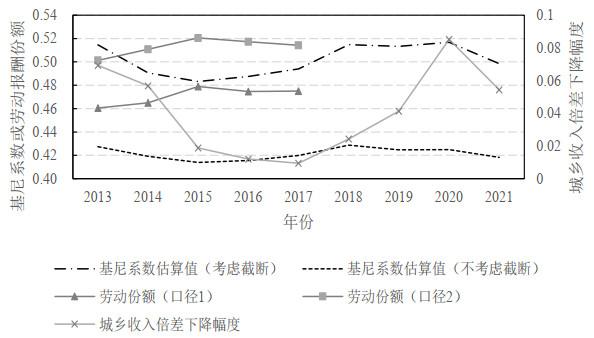
另外, 劳动报酬份额也是反映收入差距的重要指标. 根据张军等(2022)的测算, 不论是基于《中国统计年鉴》数据(口径1)还是中国投入产出表数据(口径2)算出的2013–2017年的劳动报酬份额均以2015年为转折点先上升后下降, 这与图中所呈现的收入差距变化情况恰好吻合.
图 7则展示了在考虑截断情况下采用Dagum分布还原分组数据计算出的中等收入群体占比, 收入参考标准为国家统计局的"中国典型的三口之家的年收入在10
图7
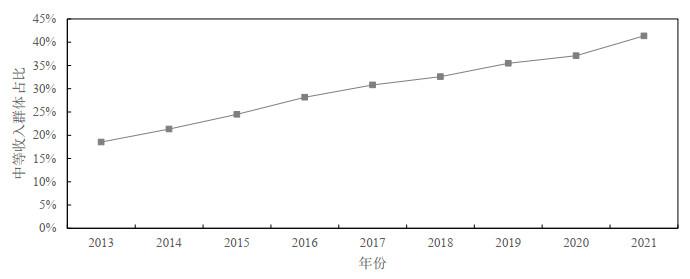
10各年中等收入群体的标准为以2017年为基期根据居民消费价格指数调整所得.
受篇幅所限, 本文无法对相关实际应用结果进行全面展示. 后续研究可以基于本文的发现, 对中国不同层面的的收入不均等、中等收入群体占比、贫困等收入分配问题进行更为详细的分析, 或者通过控制这些重要变量获得更为可靠的研究发现与结论.
6 小结
不均等、贫困和中等收入群体占比等收入分配指标, 不但自身非常重要, 而且是影响众多经济关系的关键变量之一, 但相关数据的缺失不仅阻碍了收入分配领域的研究进展, 还使得实证研究无法将其纳入相关研究框架. 幸运的是, 不少国家和地区公布收入分组数据, 为通过使用Shorrocks and Wan (2009)的方法还原数据, 然后估算这些指标提供了可能.
但是, Shorrocks and Wan (2009)的方法依赖于预设的统计分布函数, 而且没有考虑数据缺失问题. 基于CFPS2018数据进行蒙特卡罗实验, 本文首先评估了常用分布函数的表现, 结果发现Dagum分布的表现相对较优. 此外, 本文还发现, Shorrocks and Wan (2009)提出的迭代法可以改善还原数据的可靠性. 接着, 本文引入条件分布以填补数据缺失. 蒙特卡罗实验结果显示, 使用条件分布可以在相当程度上解决数据截断问题, 而且Dagum分布的表现最佳. 最后, 本文基于国家统计局公布的收入分组数据估算了中国的基尼系数和中等收入群体占比指标, 并据此进行了简单的分析讨论.
应当说明的是, 本文的研究具有一定的局限性. 一是假定不同收入群体的数据服从同一分布; 二是除截断部分(低收入或高收入部分) 以外, 不存在或少有其他数据问题. 一般来说, 分布函数的参数越多, 其还原效果越好. 但由于分组数据所能提供的信息有限, 过多的参数可能导致拟合结果不稳定, 这一问题在使用条件分布法时尤为突出. 如果能够通过其他途径预先获得数据缺失的比例, 应该可以得到更为可靠的还原数据.
附录
表A1 不同截断比例下贫困率的平均绝对百分比偏差(单位: %)
| 分组数 | 指标 | 截断比例 | Lognormal | Gamma | Dagum | SM | Beta2 | GB2 |
| 五等份分组 | Poverty2300 | 0.50% | 28.52 | 81.89 | 39.83 | 21.06 | 10.37 | 14.04 |
| 1.00% | 35.67 | 71.19 | 33.38 | 22.80 | 5.67 | 9.67 | ||
| 1.50% | 42.04 | 61.22 | 30.39 | 22.40 | 6.91 | 9.16 | ||
| 2.00% | 47.72 | 51.78 | 26.28 | 19.87 | 8.01 | 11.43 | ||
| 2.50% | 52.80 | 42.69 | 20.93 | 16.78 | 9.87 | 13.24 | ||
| 3.00% | 56.95 | 33.85 | 17.04 | 13.40 | 11.69 | 12.48 | ||
| Poverty19 | 0.50% | 22.24 | 63.72 | 29.36 | 14.76 | 7.75 | 11.15 | |
| 1.00% | 29.26 | 55.43 | 24.33 | 16.14 | 5.46 | 7.57 | ||
| 1.50% | 35.48 | 47.60 | 21.78 | 16.03 | 6.97 | 8.02 | ||
| 2.00% | 41.07 | 40.09 | 18.26 | 13.95 | 8.30 | 10.42 | ||
| 2.50% | 46.10 | 32.82 | 14.50 | 11.35 | 10.15 | 11.63 | ||
| 3.00% | 50.22 | 25.67 | 11.36 | 8.68 | 11.80 | 11.57 | ||
| Poverty32 | 0.50% | 2.99 | 37.39 | 17.15 | 10.47 | 6.22 | 7.16 | |
| 1.00% | 8.54 | 33.11 | 14.04 | 11.26 | 3.51 | 5.37 | ||
| 1.50% | 13.55 | 28.91 | 12.23 | 10.98 | 3.31 | 4.75 | ||
| 2.00% | 18.24 | 24.76 | 9.92 | 9.49 | 3.29 | 5.18 | ||
| 2.50% | 22.63 | 20.73 | 7.76 | 7.64 | 4.22 | 6.11 | ||
| 3.00% | 26.31 | 16.79 | 5.81 | 5.89 | 5.34 | 5.94 | ||
| 十等份分组 | Poverty2300 | 0.50% | 17.60 | 95.63 | 18.30 | 8.11 | 7.99 | 7.78 |
| 1.00% | 29.76 | 82.29 | 11.60 | 5.60 | 9.69 | 8.73 | ||
| 1.50% | 39.52 | 70.21 | 7.16 | 5.56 | 13.66 | 11.97 | ||
| 2.00% | 47.65 | 59.02 | 7.55 | 8.73 | 18.84 | 18.12 | ||
| 2.50% | 54.15 | 48.32 | 10.98 | 13.42 | 24.42 | 24.34 | ||
| 3.00% | 57.39 | 37.73 | 12.96 | 17.89 | 30.12 | 30.65 | ||
| Poverty19 | 0.50% | 12.89 | 73.76 | 11.49 | 4.82 | 8.32 | 7.10 | |
| 1.00% | 23.19 | 63.93 | 6.75 | 4.38 | 9.84 | 8.42 | ||
| 1.50% | 32.65 | 54.39 | 5.58 | 6.43 | 13.68 | 12.06 | ||
| 2.00% | 40.75 | 45.38 | 8.46 | 10.22 | 18.31 | 17.69 | ||
| 2.50% | 47.19 | 36.75 | 12.76 | 14.77 | 23.19 | 23.17 | ||
| 3.00% | 50.43 | 28.21 | 14.86 | 18.82 | 28.21 | 28.63 | ||
| Poverty32 | 0.50% | 5.17 | 35.09 | 6.97 | 3.71 | 2.00 | 2.62 | |
| 1.00% | 9.84 | 31.29 | 4.30 | 2.52 | 2.86 | 2.86 | ||
| 1.50% | 14.24 | 27.59 | 2.85 | 2.44 | 4.62 | 4.28 | ||
| 2.00% | 18.31 | 24.05 | 3.78 | 4.06 | 6.97 | 6.85 | ||
| 2.50% | 22.37 | 21.33 | 6.08 | 6.59 | 9.82 | 9.92 | ||
| 3.00% | 24.89 | 18.03 | 7.48 | 9.14 | 13.13 | 13.31 |
表A2 不同截断比例下中等收入占比的平均绝对百分比偏差(单位: %)
| 分组数 | 指标 | 截断比例 | Lognormal | Gamma | Dagum | SM | Beta2 | GB2 |
| 五等份分组 | Mid1 | 0.50% | 0.80 | 3.81 | 1.96 | 0.66 | 1.01 | 1.02 |
| 1.00% | 2.90 | 2.82 | 1.27 | 0.63 | 1.49 | 1.24 | ||
| 1.50% | 4.42 | 2.56 | 0.97 | 0.58 | 1.45 | 1.22 | ||
| 2.00% | 5.53 | 2.61 | 0.87 | 0.59 | 1.55 | 1.37 | ||
| 2.50% | 6.46 | 2.83 | 1.06 | 0.63 | 1.80 | 1.63 | ||
| 3.00% | 7.14 | 3.15 | 1.39 | 0.63 | 2.03 | 1.78 | ||
| Mid2 | 0.50% | 1.27 | 4.80 | 2.92 | 1.54 | 1.23 | 1.45 | |
| 1.00% | 1.60 | 4.04 | 2.97 | 1.53 | 1.14 | 1.21 | ||
| 1.50% | 1.97 | 3.22 | 3.04 | 1.42 | 1.19 | 1.23 | ||
| 2.00% | 2.44 | 2.42 | 3.06 | 1.31 | 1.23 | 1.34 | ||
| 2.50% | 2.95 | 1.71 | 3.01 | 1.26 | 1.28 | 1.21 | ||
| 3.00% | 3.41 | 1.24 | 2.93 | 1.20 | 1.34 | 1.22 | ||
| 十等份分组 | Mid1 | 0.50% | 1.12 | 1.97 | 0.93 | 0.65 | 1.73 | 1.42 |
| 1.00% | 2.87 | 1.08 | 0.47 | 0.88 | 1.85 | 1.56 | ||
| 1.50% | 4.19 | 1.11 | 0.88 | 1.35 | 2.11 | 1.94 | ||
| 2.00% | 5.19 | 1.50 | 1.68 | 1.94 | 2.53 | 2.51 | ||
| 2.50% | 6.02 | 2.02 | 2.55 | 2.69 | 3.18 | 3.22 | ||
| 3.00% | 6.69 | 2.61 | 2.96 | 3.35 | 3.88 | 3.93 | ||
| Mid2 | 0.50% | 0.81 | 5.92 | 2.43 | 1.38 | 0.73 | 1.03 | |
| 1.00% | 1.06 | 4.97 | 2.45 | 1.34 | 0.69 | 0.86 | ||
| 1.50% | 0.91 | 4.02 | 2.54 | 1.36 | 0.72 | 0.72 | ||
| 2.00% | 0.83 | 3.05 | 2.75 | 1.50 | 0.78 | 0.73 | ||
| 2.50% | 1.17 | 2.07 | 2.61 | 1.65 | 0.86 | 0.83 | ||
| 3.00% | 1.57 | 1.20 | 2.19 | 1.48 | 0.94 | 0.95 |
表A3 调整后各分位内收入份额平均绝对偏差(%) (五等份分组数据, 模拟100次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| 1 | 0.02 | 0.02 | 0.03 | 0.02 | 0.02 | 0.02 | 0.02 | 0.04 |
| 2 | 0.04 | 0.03 | 0.05 | 0.02 | 0.02 | 0.03 | 0.02 | 0.08 |
| 3 | 0.05 | 0.04 | 0.07 | 0.03 | 0.03 | 0.04 | 0.03 | 0.13 |
| 4 | 0.06 | 0.05 | 0.09 | 0.05 | 0.04 | 0.04 | 0.04 | 0.20 |
| 5 | 0.08 | 0.07 | 0.11 | 0.06 | 0.06 | 0.06 | 0.06 | 0.26 |
| 6 | 0.10 | 0.10 | 0.14 | 0.07 | 0.07 | 0.08 | 0.07 | 0.36 |
| 7 | 0.13 | 0.14 | 0.20 | 0.09 | 0.10 | 0.10 | 0.10 | 0.50 |
| 8 | 0.29 | 0.43 | 0.45 | 0.14 | 0.15 | 0.19 | 0.14 | 1.04 |
| 9 | 1.44 | 3.90 | 3.22 | 0.32 | 0.47 | 0.90 | 0.51 | 3.20 |
| 10 | 9.68 | 16.03 | 13.18 | 4.16 | 5.14 | 7.10 | 5.31 | 13.69 |
| total | 11.89 | 20.81 | 17.53 | 4.97 | 6.10 | 8.56 | 6.30 | 19.49 |
表A4 调整前各分位内收入份额平均绝对偏差(%) (五等份分组数据, 模拟100次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| 1 | 0.04 | 0.07 | 0.67 | 0.03 | 0.02 | 0.02 | 0.02 | 0.14 |
| 2 | 0.07 | 0.16 | 1.10 | 0.04 | 0.03 | 0.04 | 0.03 | 0.50 |
| 3 | 0.11 | 0.44 | 1.36 | 0.05 | 0.04 | 0.04 | 0.04 | 0.86 |
| 4 | 0.13 | 0.79 | 1.57 | 0.07 | 0.05 | 0.05 | 0.05 | 1.19 |
| 5 | 0.15 | 1.17 | 1.77 | 0.09 | 0.06 | 0.07 | 0.06 | 1.62 |
| 6 | 0.18 | 1.58 | 1.86 | 0.11 | 0.08 | 0.09 | 0.08 | 2.11 |
| 7 | 0.22 | 2.02 | 1.96 | 0.14 | 0.10 | 0.13 | 0.10 | 2.84 |
| 8 | 0.60 | 2.43 | 2.10 | 0.19 | 0.15 | 0.31 | 0.14 | 3.74 |
| 9 | 1.64 | 2.72 | 3.73 | 0.33 | 0.49 | 1.01 | 0.53 | 4.49 |
| 10 | 9.57 | 15.04 | 16.42 | 4.16 | 5.09 | 7.01 | 5.25 | 20.01 |
| total | 12.69 | 26.42 | 32.51 | 5.21 | 6.11 | 8.77 | 6.28 | 37.49 |
表A5 调整后各分位内收入份额平均绝对偏差(%) (十等份分组数据, 模拟100次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| 1 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.03 |
| 2 | 0.02 | 0.03 | 0.03 | 0.02 | 0.02 | 0.02 | 0.02 | 0.05 |
| 3 | 0.04 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.07 |
| 4 | 0.05 | 0.05 | 0.05 | 0.04 | 0.04 | 0.04 | 0.04 | 0.10 |
| 5 | 0.06 | 0.07 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 | 0.12 |
| 6 | 0.08 | 0.09 | 0.08 | 0.07 | 0.07 | 0.07 | 0.07 | 0.17 |
| 7 | 0.09 | 0.12 | 0.10 | 0.09 | 0.09 | 0.09 | 0.09 | 0.22 |
| 8 | 0.12 | 0.16 | 0.13 | 0.12 | 0.12 | 0.12 | 0.12 | 0.31 |
| 9 | 0.33 | 0.37 | 0.39 | 0.26 | 0.27 | 0.29 | 0.28 | 0.83 |
| 10 | 9.68 | 16.46 | 12.87 | 4.04 | 4.92 | 6.92 | 5.32 | 11.95 |
| total | 10.49 | 17.39 | 13.77 | 4.76 | 5.64 | 7.66 | 6.06 | 13.85 |
表A6 调整前各分位内收入份额平均绝对偏差(%) (十等份分组数据, 模拟100次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| 1 | 0.05 | 0.05 | 0.31 | 0.02 | 0.02 | 0.03 | 0.06 | 0.16 |
| 2 | 0.10 | 0.30 | 0.66 | 0.05 | 0.03 | 0.04 | 0.09 | 0.53 |
| 3 | 0.12 | 0.65 | 1.06 | 0.06 | 0.04 | 0.05 | 0.11 | 0.92 |
| 4 | 0.15 | 0.99 | 1.24 | 0.07 | 0.05 | 0.06 | 0.11 | 1.25 |
| 5 | 0.19 | 1.35 | 1.48 | 0.09 | 0.06 | 0.07 | 0.12 | 1.69 |
| 6 | 0.22 | 1.71 | 1.59 | 0.12 | 0.08 | 0.10 | 0.14 | 2.25 |
| 7 | 0.26 | 2.06 | 1.68 | 0.16 | 0.11 | 0.15 | 0.17 | 3.09 |
| 8 | 0.57 | 2.34 | 1.92 | 0.20 | 0.17 | 0.28 | 0.22 | 4.02 |
| 9 | 1.64 | 2.62 | 4.15 | 0.35 | 0.42 | 0.97 | 0.47 | 4.84 |
| 10 | 9.58 | 15.44 | 15.04 | 4.09 | 4.91 | 6.90 | 5.37 | 22.79 |
| total | 12.87 | 27.51 | 29.13 | 5.23 | 5.89 | 8.66 | 6.85 | 41.55 |
表A7 调整后各指标平均绝对百分比偏差(%) (五等份分组数据, 模拟100次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| Gini | 1.41 | 3.46 | 2.56 | 0.23 | 0.47 | 0.90 | 0.52 | 2.40 |
| Poverty2300 | 19.65 | 2.94 | 20.08 | 2.49 | 3.02 | 8.68 | 3.49 | 100.00 |
| Poverty19 | 13.78 | 2.65 | 7.61 | 3.53 | 4.91 | 8.25 | 5.11 | 100.00 |
| Poverty32 | 3.18 | 3.19 | 4.80 | 1.99 | 1.44 | 0.89 | 1.38 | 27.77 |
| Mid1 | 2.66 | 2.88 | 3.30 | 0.52 | 0.80 | 1.63 | 0.85 | 4.93 |
| Mid2 | 1.22 | 1.27 | 1.57 | 1.12 | 1.10 | 1.21 | 1.10 | 2.20 |
表A8 调整前各指标平均绝对百分比偏差(%) (五等份分组数据, 模拟100次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| Gini | 1.14 | 15.08 | 20.46 | 0.49 | 0.70 | 0.95 | 0.72 | 9.98 |
| Poverty2300 | 25.98 | 24.19 | 308.54 | 4.37 | 2.82 | 10.68 | 3.43 | 100.00 |
| Poverty19 | 20.14 | 13.67 | 243.09 | 2.30 | 4.48 | 10.22 | 5.11 | 100.00 |
| Poverty32 | 1.31 | 1.35 | 135.96 | 2.03 | 1.69 | 1.17 | 1.67 | 100.00 |
| Mid1 | 3.07 | 38.59 | 17.16 | 1.51 | 0.72 | 1.85 | 0.61 | 47.69 |
| Mid2 | 6.76 | 5.76 | 39.26 | 4.33 | 1.86 | 2.83 | 1.37 | 70.09 |
表A9 调整后各指标平均绝对百分比偏差(%) (十等份分组数据, 模拟100次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| Gini | 0.75 | 1.56 | 1.07 | 0.20 | 0.31 | 0.50 | 0.36 | 0.84 |
| Poverty2300 | 2.46 | 6.67 | 5.33 | 5.87 | 5.44 | 4.49 | 5.38 | 22.75 |
| Poverty19 | 1.86 | 9.08 | 11.47 | 7.55 | 7.04 | 5.22 | 6.92 | 22.86 |
| Poverty32 | 0.98 | 0.88 | 0.78 | 0.96 | 1.02 | 1.06 | 1.13 | 5.01 |
| Mid1 | 1.75 | 3.65 | 2.57 | 0.46 | 0.55 | 0.91 | 0.68 | 3.06 |
| Mid2 | 0.86 | 0.71 | 0.71 | 0.88 | 0.94 | 0.91 | 0.96 | 1.99 |
表A10 调整前各指标平均绝对百分比偏差(%) (十等份分组数据, 模拟100次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| Gini | 0.86 | 17.89 | 15.47 | 0.43 | 0.53 | 0.54 | 1.52 | 13.34 |
| Poverty2300 | 21.84 | 3.50 | 335.90 | 2.18 | 3.83 | 9.88 | 5.44 | 120.44 |
| Poverty19 | 16.21 | 5.19 | 263.91 | 4.50 | 6.19 | 9.38 | 7.70 | 114.48 |
| Poverty32 | 2.78 | 12.58 | 145.05 | 3.85 | 2.58 | 1.16 | 3.86 | 106.07 |
| Mid1 | 2.52 | 41.02 | 2.09 | 2.18 | 0.89 | 1.31 | 2.47 | 50.07 |
| Mid2 | 7.54 | 1.70 | 41.43 | 4.96 | 2.17 | 2.97 | 3.70 | 66.62 |
表A11 调整后各分位内收入份额平均绝对偏差(%) (五等份分组数据, 模拟200次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| 1 | 0.02 | 0.02 | 0.03 | 0.02 | 0.02 | 0.02 | 0.02 | 0.04 |
| 2 | 0.04 | 0.02 | 0.05 | 0.02 | 0.02 | 0.03 | 0.02 | 0.08 |
| 3 | 0.05 | 0.04 | 0.07 | 0.03 | 0.03 | 0.04 | 0.03 | 0.13 |
| 4 | 0.06 | 0.05 | 0.09 | 0.05 | 0.04 | 0.04 | 0.04 | 0.20 |
| 5 | 0.08 | 0.07 | 0.11 | 0.06 | 0.06 | 0.06 | 0.06 | 0.26 |
| 6 | 0.10 | 0.10 | 0.14 | 0.07 | 0.07 | 0.08 | 0.07 | 0.36 |
| 7 | 0.13 | 0.14 | 0.20 | 0.09 | 0.10 | 0.10 | 0.10 | 0.50 |
| 8 | 0.29 | 0.44 | 0.45 | 0.14 | 0.15 | 0.19 | 0.15 | 1.04 |
| 9 | 1.44 | 3.90 | 3.20 | 0.31 | 0.47 | 0.90 | 0.54 | 3.19 |
| 10 | 9.69 | 16.00 | 13.15 | 4.22 | 5.20 | 7.14 | 5.47 | 13.66 |
| total | 11.90 | 20.78 | 17.49 | 5.02 | 6.15 | 8.60 | 6.50 | 19.47 |
表A12 调整前各分位内收入份额平均绝对偏差(%) (五等份分组数据, 模拟200次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| 1 | 0.04 | 0.07 | 0.66 | 0.03 | 0.02 | 0.02 | 0.05 | 0.14 |
| 2 | 0.07 | 0.16 | 1.08 | 0.04 | 0.03 | 0.04 | 0.05 | 0.50 |
| 3 | 0.11 | 0.44 | 1.35 | 0.06 | 0.04 | 0.04 | 0.06 | 0.86 |
| 4 | 0.13 | 0.79 | 1.57 | 0.07 | 0.05 | 0.05 | 0.07 | 1.19 |
| 5 | 0.15 | 1.17 | 1.78 | 0.09 | 0.06 | 0.07 | 0.08 | 1.61 |
| 6 | 0.17 | 1.58 | 1.88 | 0.12 | 0.08 | 0.09 | 0.09 | 2.12 |
| 7 | 0.22 | 2.01 | 1.98 | 0.14 | 0.10 | 0.13 | 0.11 | 2.85 |
| 8 | 0.59 | 2.41 | 2.11 | 0.19 | 0.15 | 0.30 | 0.15 | 3.74 |
| 9 | 1.63 | 2.71 | 3.73 | 0.33 | 0.48 | 1.01 | 0.55 | 4.49 |
| 10 | 9.58 | 14.99 | 16.46 | 4.22 | 5.15 | 7.05 | 5.47 | 20.01 |
| total | 12.69 | 26.33 | 32.61 | 5.27 | 6.17 | 8.80 | 6.68 | 37.51 |
表13 调整后各分位内收入份额平均绝对偏差(%) (十等份分组数据, 模拟200次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| 1 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.03 |
| 2 | 0.02 | 0.03 | 0.03 | 0.02 | 0.02 | 0.02 | 0.02 | 0.05 |
| 3 | 0.04 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.07 |
| 4 | 0.05 | 0.05 | 0.05 | 0.04 | 0.04 | 0.04 | 0.04 | 0.10 |
| 5 | 0.06 | 0.07 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 | 0.12 |
| 6 | 0.08 | 0.09 | 0.08 | 0.07 | 0.07 | 0.07 | 0.07 | 0.16 |
| 7 | 0.09 | 0.12 | 0.10 | 0.09 | 0.09 | 0.09 | 0.09 | 0.22 |
| 8 | 0.12 | 0.16 | 0.14 | 0.13 | 0.12 | 0.12 | 0.12 | 0.32 |
| 9 | 0.32 | 0.37 | 0.38 | 0.25 | 0.27 | 0.29 | 0.27 | 0.83 |
| 10 | 9.70 | 16.45 | 12.87 | 4.11 | 4.97 | 6.96 | 5.24 | 11.77 |
| total | 10.50 | 17.38 | 13.76 | 4.82 | 5.70 | 7.69 | 5.97 | 13.66 |
表14 调整前各分位内收入份额平均绝对偏差(%) (十等份分组数据, 模拟200次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| 1 | 0.05 | 0.05 | 0.31 | 0.02 | 0.02 | 0.03 | 0.04 | 0.15 |
| 2 | 0.10 | 0.30 | 0.66 | 0.05 | 0.03 | 0.04 | 0.06 | 0.52 |
| 3 | 0.12 | 0.64 | 1.06 | 0.06 | 0.04 | 0.05 | 0.07 | 0.90 |
| 4 | 0.15 | 0.99 | 1.24 | 0.07 | 0.05 | 0.06 | 0.08 | 1.23 |
| 5 | 0.18 | 1.35 | 1.48 | 0.09 | 0.06 | 0.07 | 0.09 | 1.67 |
| 6 | 0.22 | 1.71 | 1.59 | 0.12 | 0.08 | 0.10 | 0.10 | 2.23 |
| 7 | 0.26 | 2.05 | 1.68 | 0.16 | 0.11 | 0.15 | 0.14 | 3.06 |
| 8 | 0.56 | 2.33 | 1.92 | 0.20 | 0.17 | 0.27 | 0.19 | 3.99 |
| 9 | 1.63 | 2.60 | 4.14 | 0.35 | 0.42 | 0.97 | 0.45 | 4.78 |
| 10 | 9.60 | 15.40 | 15.06 | 4.16 | 4.97 | 6.95 | 5.26 | 22.31 |
| total | 12.87 | 27.41 | 29.14 | 5.30 | 5.95 | 8.69 | 6.49 | 40.84 |
表A15 调整后各指标平均绝对百分比偏差(%) (五等份分组数据, 模拟200次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| Gini | 1.40 | 3.45 | 2.55 | 0.22 | 0.48 | 0.90 | 0.55 | 2.40 |
| Poverty2300 | 19.62 | 2.92 | 20.46 | 2.31 | 2.82 | 8.51 | 3.80 | 100.00 |
| Poverty19 | 13.82 | 2.48 | 7.63 | 3.43 | 4.85 | 8.20 | 5.30 | 100.00 |
| Poverty32 | 3.18 | 3.22 | 4.89 | 2.01 | 1.46 | 0.91 | 1.44 | 27.80 |
| Mid1 | 2.70 | 3.00 | 3.29 | 0.58 | 0.86 | 1.67 | 0.95 | 5.02 |
| Mid2 | 1.14 | 1.25 | 1.52 | 1.08 | 1.04 | 1.13 | 1.05 | 2.20 |
表A16 调整前各指标平均绝对百分比偏差(%) (五等份分组数据, 模拟200次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| Gini | 1.13 | 15.04 | 20.67 | 0.49 | 0.70 | 0.95 | 1.11 | 9.99 |
| Poverty2300 | 25.97 | 24.65 | 312.27 | 4.52 | 2.63 | 10.47 | 3.77 | 100.00 |
| Poverty19 | 20.20 | 13.95 | 246.07 | 2.07 | 4.33 | 10.14 | 5.59 | 100.00 |
| Poverty32 | 1.39 | 1.32 | 137.27 | 2.03 | 1.71 | 1.20 | 2.17 | 100.00 |
| Mid1 | 2.88 | 38.21 | 16.80 | 1.62 | 0.70 | 1.70 | 0.94 | 47.78 |
| Mid2 | 6.62 | 5.65 | 39.64 | 4.45 | 1.90 | 2.72 | 2.64 | 70.30 |
表A17 调整后各指标平均绝对百分比偏差(%) (十等份分组数据, 模拟200次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| Gini | 0.75 | 1.56 | 1.07 | 0.20 | 0.31 | 0.51 | 0.34 | 0.82 |
| Poverty2300 | 2.49 | 6.45 | 5.11 | 5.70 | 5.29 | 4.42 | 5.22 | 23.31 |
| Poverty19 | 1.80 | 9.07 | 11.39 | 7.50 | 6.99 | 5.18 | 6.88 | 22.98 |
| Poverty32 | 1.01 | 0.91 | 0.77 | 0.98 | 1.06 | 1.10 | 1.11 | 5.02 |
| Mid1 | 1.78 | 3.89 | 2.60 | 0.53 | 0.63 | 0.99 | 0.70 | 2.68 |
| Mid2 | 0.89 | 0.76 | 0.77 | 0.87 | 0.95 | 0.93 | 0.96 | 1.97 |
表A18 调整前各指标平均绝对百分比偏差(%) (十等份分组数据, 模拟200次)
| 分布 | Lognormal | Gamma | Weibull | Dagum | SM | Beta2 | GB2 | Pareto |
| Gini | 0.85 | 17.85 | 15.56 | 0.43 | 0.53 | 0.54 | 1.02 | 13.00 |
| Poverty2300 | 21.80 | 3.60 | 338.48 | 2.01 | 3.62 | 9.71 | 4.66 | 110.22 |
| Poverty19 | 16.24 | 4.89 | 265.51 | 4.37 | 6.08 | 9.32 | 7.01 | 107.24 |
| Poverty32 | 2.77 | 12.44 | 145.79 | 3.83 | 2.59 | 1.17 | 3.18 | 103.04 |
| Mid1 | 2.36 | 40.64 | 1.86 | 2.31 | 0.99 | 1.16 | 1.72 | 49.91 |
| Mid2 | 7.41 | 1.64 | 41.39 | 5.09 | 2.25 | 2.86 | 2.79 | 66.97 |
参考文献
中国隐性收入规模估计——基于扩展消费支出模型及数据的解读
[J].
Estimating the Size of Hidden Income in China-An Interpretation Based on the Extended Consumption Expenditure Model and Data
[J].
收入差距与刑事犯罪: 基于中国省级面板数据的经验研究
[J].
Income Disparity and Criminal Crime: An Empirical Study Based on Provincial Panel Data in China
[J].
收入分布函数在收入不平等研究领域的应用
[J].
Application of Income Distribution Function in the Field of Income Inequality Research
[J].
中国总体收入基尼系数的估计: 1985-2008
[J].
Estimation of the Gini Coeffcient of Overall Income in China: 1985-2008
[J].
中国收入差距究竟有多大?——对修正样本结构偏差的尝试
[J].
How Big is the Income Gap in China?-An Attempt to Correct for Sample Structure Bias
[J].
谁的上升空间受到了挤压: 收入流动性角度的分析
[J].
Whose Upside is Squeezed: An Analysis from the Perspective of Income Mobility
[J].
中等收入群体比重变动的因素分解——基于收入极化指数的经验证据
[J].
Factor Decomposition of the Change in the Share of Middle-income Group-Empirical Evidence Based on Income Polarization Index
[J].
因患寡, 而患不均——中国的收入差距、投资、教育和增长的相互影响
[J].
Unevenness Because of Scarcity-The Interplay of Income Disparity, Investment, Education and Growth in China
[J].
高收入人群缺失与收入差距低估
[J].
The Absence of High-income People and the Underestimation of Income Disparity
[J].
分组数据下收入基尼系数的计算误差分析
[J].
Error Analysis of the Calculation of Income Gini Coeffcient Under Grouped Data
[J].
中国减贫战略转型及其面临的挑战
[J].
China's Poverty Reduction Strategy Transformation and the Challenges it Faces
[J].
灰色收入拉大居民收入差距
[J].
Gray Income Widens the Income Gap Among Residents
[J].
中国省际物质资本存量估算: 1952-2000
[J].
Estimation of Inter-provincial Physical Capital Stock in China: 1952-2000
[J].
中国劳动报酬份额变化的动态一般均衡分析
[J].
Dynamic General Equilibrium Analysis of the Change of Labor Compensation Share in China
[J].
城镇居民收入分布函数的研究
[J].
Research on the Distribution Function of Urban Residents' Income
[J].
中国省际无形资本存量估算: 2000-2016年
[J].
Estimation of Inter-provincial Intangible Capital Stock in China: 2000 to 2016
[J].
Top Indian Incomes, 1922-2000
[J].
Estimating trends in US income Inequality Using the Current Population Survey: The Importance of Controlling for Censoring
[J].
A New Model of Personal Income Distribution: Specification and Estimation
[J].
Measuring Poverty in a Growing World (or Measuring Growth in a Poor World)
[J].
The Estimation of the Lorenz Curve and Gini Index
[J].
Shrinking Share of Middle-income Group in Germany and the US
[J].
Inference for Income Distributions Using Grouped Data
[J].
On the Estimation of Income Inequality Measures from Grouped Observations
[J].
On the Estimation of Lorenz Curves from Grouped Observations
[J].
A Decomposition Analysis of Regional Poverty in Russia
[J].
An Econometric Method of Correcting for Unit Nonresponse Bias in Surveys
[J].
Survey Nonresponse and the Distribution of Income
[J].
Characterization of the Pareto Distribution Through a Model of Underreported Incomes
[J].
Some Generalized Functions for the Size Distribution of Income
[J].
A Generalization of the Beta Distribution with Applications
[J].
Estimation of the Shape and Scale Parameters of the Weibull Distribution
[J].
Income Inequality in France, 1901-1998
[J].
The Middle Class Throughout the World in the Mid-2000s
[J].
A Convenient Descriptive Model of Income Distribution: The Gamma Density
[J].
A Function for Size Distribution of Incomes
[J].
A Measure of Income Inequality in the U.S. for the Years 1952-1980 Based on the Beta Distribution of the Second Kind
[J].
The Lognormal Distribution
[J].
Understanding Regional Poverty and Inequality Trends in China: Methodological Issues and Empirical Findings
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}