


1 引言
量化估计一项政策干预的因果效应是许多经济学实证研究的基本目标.围绕这一目标, 已有文献主要在各种假设下考虑了总体的平均处理效应(average treatment effect, ATE)或仅针对处理组的平均处理效应(average treatment effect on the treated, ATT)的识别与估计.这方面比较有影响的综述文献包括: Angrist andKrueger (1999), Heckman, Lalonde and Smith (1999), Blundell and Dias (2002)等.在最近的综述文献中, Imbens (2004), Imbens and Wooldridge (2009)对处理效应这一研究主题的最新进展作了较全面的回顾.
虽然平均处理效应在衡量政策干预的因果效应方面非常重要, 但它并不能反映政策干预对目标变量分布影响的全貌.比如当施行一项政策后, 均值处理效应并不能衡量结果变量分布的方差是否发生了改变, 均值处理效应也不能反映政策干预对目标变量分布的影响, 包括在不同分位点的异质性影响.事实上, 有关目标变量分布方面的信息在许多应用中是非常重要的, 尤其在政策制定方面.例如, Freeman (1980), Card (1996)研究工会对工资差距的影响, Lalonde (1995), Abadie, Angrist and Imbens (2002)考虑政府培训项目对处于不同收入分布位置人群的影响, 以及政府补贴储蓄计划对处于储蓄分布低分位数人群的影响等.从政策制定的角度来说, 即使两项处理的平均处理效应是相同的, 政府更青睐有助于改善低收入群体处境的政策选择.为了刻画政策干预对目标变量的分布效应, Lehmann (1975), Doksum (1974)引入的分位数处理效应(quantile treatment effect, QTE)可作为一种直观且有效的工具.有关分位数处理效应的最新研究包括:Abadie et al. (2002), Chernozhukov and Hansen (2005), Donald and Hsu (2014), Firpo (2007), Frölich and Melly (2013)等.
政策评估文献中存在的另一个挑战是如何刻画Heckman and Robb (1985), Heckman, Smith and Clements (1997)所提到的处理变量对具有不同特征个体的异质效应.由于处理对不同个体的效应存在异质性, 因此研究者除了关心处理变量对整个总体的效应之外, 有时也关心政策对具有特定特征的子群体的效应.例如, 当估计母亲在怀孕期间吸烟对婴儿出生体重的影响时, 研究者感兴趣的可能是不同年龄段母亲吸烟对婴儿出生体重的异质效应.为此, Abrevaya, Hsu and Lieli (2015), Lee, Okui and Whang (2017)使用部分条件平均处理效应(partially conditional average treatment effect, PCATE)来刻画处理变量对具有不同特征子群体的条件平均效应.
本文试图提出一种新的处理效应模型来刻画处理变量对具有不同特征的子群体沿着目标变量分布方向上的异质效应.为此, 在无混淆假设成立的框架下, 我们提出使用部分条件分位数处理效应(partially conditional quantile treatment effect, PCQTE)来刻画给定某一连续协变量
我们的研究动机来自于如下健康经济学中的实际问题, 即考察不同年龄段母亲在首次怀孕时, 怀孕期间吸烟对婴儿出生体重的分布效应.在最近的文献中, Abrevaya et al. (2015), Lee et al. (2017)考虑了在给定母亲不同年龄下怀孕期间吸烟对婴儿出生体重的平均处理效应, 其中Abrevaya et al. (2015)提出了一种非参数和半参数方法估计给定连续协变量下的条件平均处理效应.为了避免非参数估计中的维数灾难问题, Lee et al. (2017)则基于参数回归模型提出了一种双稳健方法估计给定连续协变量下的条件平均处理效应.然而, 以上两篇文献都没有考虑在给定母亲年龄下, 母亲在怀孕期间吸烟对婴儿出生体重的异质分布效应.事实上, 我们的研究发现, 不管对白人还是黑人来说, 婴儿出生体重的分布都是非对称且厚尾的.因此, 本文提出的方法可能更适合分析这一实际数据.同时, 我们也将考察在母亲不同年龄下, 接受处理群体中的母亲在怀孕期间吸烟对婴儿出生体重的分位数处理效应, 即处理组下的部分条件分位数处理效应(partially conditional quantile treatment effect on the treated, PCQTT).总的来说, 我们的实证结果表明在不同母亲年龄组之间分位数处理效应存在实质性的差异, 在所有怀孕母亲年龄段中以及在所有分位数水平下, 母亲吸烟对婴儿出生体重均会产生显著的负效应.但是, 我们也发现, 当母亲年龄较大时, 母亲吸烟对婴儿出生体重的分位数效应会变得更强.对于白人母亲群体而言, 在给定母亲年龄的情况下, 部分条件分位数处理效应在低分位数水平的数值要大于其在中位数或较高分位数水平的数值, 而在黑人母亲群体中这一现象则不显著.
本文余下部分的具体安排如下: 第二部分介绍部分条件分位数处理效应(PCQTE和PCQTT)模型并讨论它们的识别条件以及估计方法, 并进一步给出估计量的渐近性质; 第三部分使用蒙特卡罗模拟来考察相应估计量的有限样本性质; 第四部分实证研究母亲在怀孕期间吸烟对婴儿出生体重的分位数处理效应如何在母亲的不同年龄组之间变化; 第五部分则是结论.附录包含了所有的理论证明.
2 部分条件分位数处理效应模型
2.1 模型框架
假定
此外, 我们用
假设 1 (i) (无混淆处理分配) 给定协变量
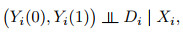
其中
(ii) (共同支撑集) 对
其中
在统计学或计量经济学文献中, 假设1 (i)通常也称为"条件无混淆假设"条件独立性假设"或者"基于可观测选择假设"等, 相关文献可参见Rosenbaum and Rubin (1983), Lechner (1999, 2002).这一假设排除了那些不可观测的因素同时影响干预选择和潜在结果变量的情况.假设1 (ii)表明在整个总体中对于几乎所有的
本文感兴趣的是在给定观测协变量
其中
2.2 估计方法
因为我们无法同时观测到每个个体的潜在结果变量
因而
其中
由于在实际应用中
其中, 对于
这里
进而可得到
接下来的问题是如何获得
2.3 理论性质
在这一部分, 我们研究(3) 中提出的半参数估计
假设 2 (
假设 3 (i) 对于
假设 4 (核函数和窗框) (i) 核函数
假设 5 (参数倾向得分函数) 假设倾向得分函数具有参数形式
假设2中关于
接下来我们在下面的定理中给出估计
定理 1 在假设1
其中
根据定理1, 我们可知(6) 中的第一项是半参数估计
其中
其中对于
2.4 PCQTT的估计
一般来说, 政策制定者除了对整个总体的处理效应感兴趣之外, 还可能对处理组这一群体的处理效应感兴趣, 相关文献可参见Heckman and Robb (1985), Heckman et al. (1999).当然, 在处理组这一群体中, 处理变量对每个个体的处理效应也可能是异质的.因此, 我们在这一部分考虑处理组的部分条件分位数处理效应(partially conditional quantile treatment effect on the treated, PCQTT), 其定义为:
其中
为了给出
因此, 类似于前面的(2) 式, 条件分位数函数
由此, 我们可得到PCQTT参数
其中,
这里
假设 3* (i) 对于
为了符号表示简单起见, 我们记
类似于定理1, 以下定理总结了半参数估计
定理 2 在假设1, 2, 3*, 4以及5下, 对于
其中
其它记号与定理1中具有相同的含义.
3 蒙特卡罗模拟
在这一部分, 我们使用蒙特卡罗模拟试验来考察前面提出估计方法的有限样本性质, 其目的是考察提出估计方法在各种情形下的有限样本表现.
例 1 我们考虑使用潜在结果变量
1有关Skorohod表示的定义, 读者可参见Durrett(1996).
其中
此外, 条件变量
其中
为了考察估计
其中
表1
估计
| MADE | MADE | MADE | MADE | MADE | MADE | MADE | MADE | MADE | |||
| 0.1 | 0.090 (0.022) | 0.068 (0.014) | 0.060 (0.010) | 0.089 (0.020) | 0.072 (0.015) | 0.058 (0.011) | 0.101 (0.027) | 0.093 (0.020) | 0.084 (0.014) | ||
| 0.25 | 0.084 (0.020) | 0.064 (0.013) | 0.047 (0.009) | 0.080 (0.017) | 0.062 (0.013) | 0.048 (0.010) | 0.094 (0.025) | 0.083 (0.017) | 0.080 (0.012) | ||
| 0.5 | 0.080 (0.019) | 0.058 (0.012) | 0.044 (0.008) | 0.066 (0.015) | 0.049 (0.011) | 0.036 (0.008) | 0.080 (0.023) | 0.059 (0.015) | 0.045 (0.011) | ||
| 0.75 | 0.082 (0.021) | 0.062 (0.013) | 0.046 (0.009) | 0.078 (0.018) | 0.060 (0.012) | 0.045 (0.009) | 0.093 (0.025) | 0.085 (0.018) | 0.075 (0.013) | ||
| 0.9 | 0.091 (0.022) | 0.069 (0.013) | 0.061 (0.010) | 0.090 (0.020) | 0.075 (0.015) | 0.060 (0.011) | 0.098 (0.028) | 0.092 (0.021) | 0.086 (0.015) | ||
例 2 我们在第二个实验中考察前文所提出的半参数估计量
表2
估计
| MADE | MADE | MADE | MADE | MADE | MADE | MADE | MADE | MADE | |||
| 0.1 | 0.087 (0.023) | 0.063 (0.015) | 0.055 (0.010) | 0.088 (0.020) | 0.069 (0.014) | 0.054 (0.009) | 0.099 (0.027) | 0.091 (0.020) | 0.083 (0.014) | ||
| 0.25 | 0.082 (0.021) | 0.061 (0.013) | 0.046 (0.008) | 0.076 (0.017) | 0.057 (0.012) | 0.042 (0.008) | 0.092 (0.023) | 0.076 (0.017) | 0.067 (0.012) | ||
| 0.5 | 0.080 (0.019) | 0.060 (0.011) | 0.045 (0.008) | 0.068 (0.015) | 0.049 (0.010) | 0.037 (0.007) | 0.077 (0.021) | 0.058 (0.016) | 0.045 (0.011) | ||
| 0.75 | 0.083 (0.021) | 0.062 (0.013) | 0.047 (0.010) | 0.087 (0.018) | 0.065 (0.012) | 0.056 (0.009) | 0.101 (0.024) | 0.092 (0.017) | 0.083 (0.012) | ||
| 0.9 | 0.090 (0.023) | 0.066 (0.014) | 0.051 (0.011) | 0.093 (0.020) | 0.076 (0.013) | 0.064 (0.011) | 0.103 (0.028) | 0.092 (0.021) | 0.086 (0.015) | ||
4 实证分析
4.1 背景和数据描述
许多研究表明婴儿出生体重偏低与其将来的健康、教育以及劳动力市场表现相关, 但研究者对这一影响的具体大小还存在争议, 这方面的文献可参看Abrevaya (2006), Almond, Chay and Lee (2005), Currie and Almond (2011)等.众所周知, 存在许多风险因素可引起婴儿出生体重偏低, 但一般认为母亲在怀孕期间吸烟是引起婴儿出生体重偏低的最重要因素, 有关这方面的更多讨论见Kramer (1987).在过去几十年里, 许多研究者试图使用各种方法估计母亲在怀孕期间吸烟对婴儿出生体重的效应.最近有研究者使用政策评估的方法估计这种效应, 相关文献如Almond et al. (2005), Abrevaya (2006), Da Veiga and Wilder (2008), Abrevaya and Dahl (2008), Abrevaya et al. (2015)等.本文感兴趣的是母亲在怀孕期间吸烟对初生婴儿体重的分布影响如何随母亲年龄而变化.为了刻画这种异质效应, 我们使用前面提出的方法估计在给定母亲不同年龄条件下, 母亲在怀孕期间吸烟对婴儿出生体重的分位数处理效应, 而不是Abrevaya et al. (2015), Lee et al.(2017)所考虑的不同年龄下母亲孕期吸烟对初生婴儿体重的条件平均效应.在本例中, 为了满足条件无混淆假设, 已有文献通常需要控制较多的协变量, 因此与Abrevaya et al. (2015), Lee et al.(2017)类似, 我们同样使用参数方法估计未知的倾向得分函数
我们使用与Abrevaya et al. (2015)同样的数据集, 即由北卡罗来纳大学奥德姆研究所提供的1988年至2002年北卡罗来纳州健康服务中心的记录数据.我们的样本也仅使用初为人母的观察值, 并且根据文献中的通常做法, 将白人和黑人当作不同的样本处理, 其中白人样本的容量为433558, 而黑人样本的容量为157989.我们感兴趣的结果变量
图1
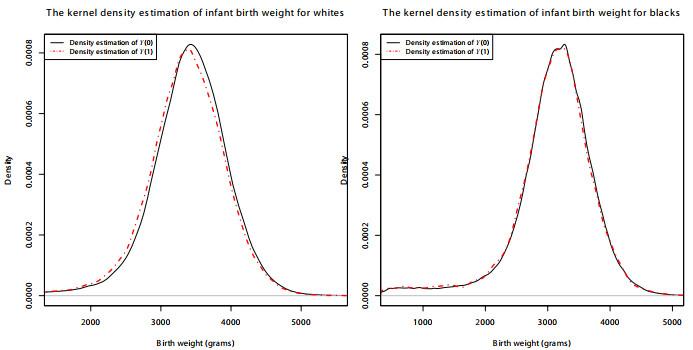
表3 描述性统计量和对称性检验结果
| Variable | Whites | Blacks | |||
| Mean | 3398.681 | 3346.848 | 3103.722 | 3082.726 | |
| Skewness | -0.846 | -0.840 | -1.181 | -1.204 | |
| Kurtosis | 5.931 | 5.734 | 6.245 | 6.164 | |
| Symmetry test( | 0.000 | 0.000 | 0.000 | 0.000 | |
| Number of observations | 359172 | 74386 | 146399 | 11590 | |
为了估计部分条件分位数处理效应函数
4.2 估计结果
图 2给出了给定母亲年龄
图2
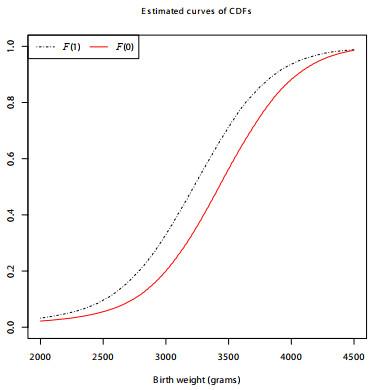
图 3给出的是在三个不同分位数水平
图3
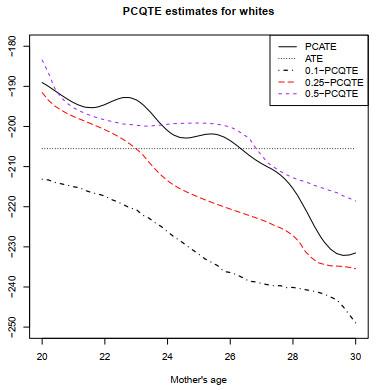
图3
三个不同分位数水平
2在最近的文章中, Tang, Cai and Fang et al. (2021)也使用这组数据考察了给定不同母亲年龄下, 母亲吸烟对婴儿出生体重的分位数处理效应是如何随母亲年龄的变化而变化的, 其得到的实证结果与本文相似.特别地, Tang et al. (2021)考虑了为
图 4给出的则是在三个不同分位数水平
图4
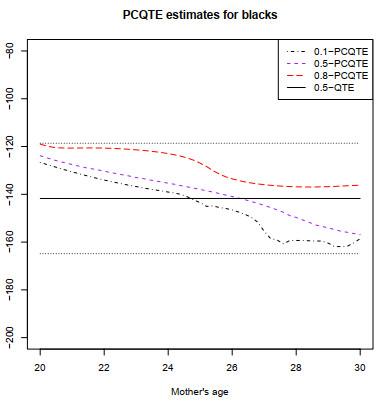
图4
三个不同分位数水平
最后, 除了上面考虑的PCQTE的估计之外, 我们也考虑了PCQTT的估计, 其估计结果展示在图 5中, 其中左图是白人的估计结果, 而右图则是黑人的估计结果.在图 5中, 我们考虑了在两个不同的分位数水平
图5
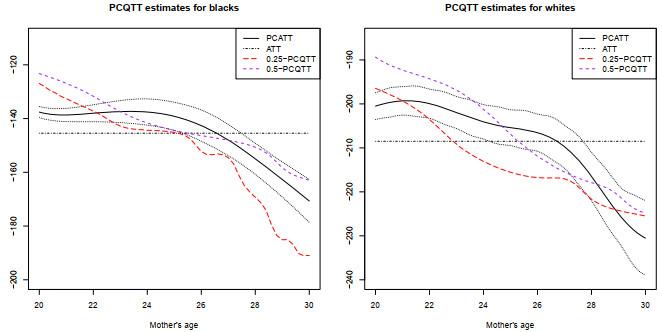
图5
两个分位数水平
5 结论
为了刻画分位数处理效应在由某一协变量定义的不同子群体之间的异质性, 我们提出了一个函数型参数—部分条件分位数处理效应, 并考虑了它的识别与估计.我们提出了一种新的估计方法并建立了其渐近性质.使用我们所提出的半参数估计方法, 我们估计了在给定不同年龄条件下, 母亲在怀孕期间吸烟对婴儿出生体重的分位数处理效应.根据实证结果, 我们发现总体而言, 当母亲年龄较大或者是在较低低分位数水平时, 吸烟对婴儿出生体重有更为严重的负效应.白人群体的条件分位数处理效应会随着母亲年龄的变化而变化, 但对黑人来说并非如此.
基于以上实证结果, 研究者可进一步探讨分位数处理效应是否随协变量
其中
附录
数学证明
在正文中, 我们有
引理 1 对于
和
其中
引理 1 的证明 根据
因此,
首先, 我们考虑
因为
现在, 我们考虑
注意到,
根据证明
和
因此, 我们可以得到:
和
于是, 我们有下面的结果:
根据(A.1, A.2和A.3), 我们有:
定理 1 的证明 对于
由简单计算可得:
其中
由此得到:
接下来我们考虑
因为
因此, 对所有的
注意到
从(A.4) 知
对所有的
这意味着
其中
和Lyapunov中心极限定理, 容易证明:
至此, 我们完成了定理的证明.
参考文献
Instrumental Variables Estimates of the Effect of Subsidized Training on the Quantiles of Trainee Earnings
[J].
Large Sample Properties of Matching Estimators for Average Treatment Effects
[J].
Matching on the Estimated Propensity Score
[J].
Estimating the Effect of Smoking on Birth Outcomes Using a Matched Panel Data Approach
[J].
The Effects of Birth Inputs on Birthweight: Evidence from Quantile Estimation on Panel Data
[J].
Estimating Conditional Average Treatment Effects
[J].
The Costs of Low Birth Weight
[J].
Empirical Strategies in Labor Economics
[J].
Alternative Approaches to Evaluation in Empirical Microeconomics
[J].
Nonparametric Quantile Estimations for Dynamic Smooth Coefficient Models
[J].
The Effect of Unions on the Structure of Wages: A Longitudinal Analysis
[J].
An Ⅳ Model of Quantile Treatment Effects
[J].
Human Capital Development before Age Five
[J].
Maternal Smoking During Pregnancy, Birthweight: A Propensity Score Matching Approach
[J].
Causal Effects in Nonexperimental Studies: Reevaluating the Evaluation of Training Programs
[J].
Empirical Probability Plots and Statistical Inference for Nonlinear Models in the Two-sample Case
[J].
Estimation and Inference for Distribution Functions and Quantile Functions in Treatment Effect Models
[J].
Efficient Semiparametric Estimation of Quantile Treatment Effects
[J].
Unionism and the Dispersion of Wages
[J].
Unconditional Quantile Treatment Effects under Endogeneity
[J].
Characterizing Selection Bias Using Experimental Data
[J].
The Economics and Econometrics of Active Labor Market Programs
[J].
Alternative Methods for Evaluating the Impact of Interventions: An Overview
[J].
Making the Most Out of Programme Evaluations and Social Experiments: Accounting for Heterogeneity in Programme Impacts
[J].
Efficient Estimation of Average Treatment Effects Using the Estimated Propensity Score
[J].
Nonparametric Estimation of Average Treatment Effects under Exogeneity: A Review
[J].
Recent Developments in the Econometrics of Program Evaluation
[J].
Regression Quantiles
[J].
Unit Root Quantile Autoregression Inference
[J].
Intrauterine Growth and Gestational Duration Determinants
[J].
The Promise of Public Sector-sponsored Training Programs
[J].
Earnings and Employment Effects of continuous Gff-the-Job Training in East Germany After Unification
[J].
Program Heterogeneity and Propensity Score Matching: An Application to the Evaluation of Active Labor Market Policies
[J].
Doubly Robust Uniform Confidence Band for the Conditional Average Treatment Effect Function
[J].
The Central Role of the Propensity Score in Observational Studies for Causal Effects
[J].
Estimating Causal Effects of Treatments in Randomized and Nonrandomized Studies
[J].
A New Quantile Treatment Effect Model for Studying Smoking Effect on Birth Weight During Mother's Pregnancy
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}