


1 引言
非平稳时间序列在经济、金融、气候科学等相关领域随处可见, 比如可支配性收入和支出, 股票价格和二氧化碳的排放量. 在过去大约二十年时间里, 非平稳时间序列的极限理论受到密切关注和长足发展, 尤其是在非线性参数模型和非参数模型的估计和检验方面, 比如, 非线性参数模型的估计理论Park and Phillips (2001), 自回归模型识别性检验Gao, King and Lu et al. (2009a), 非线性时间序列模型的非参数检验Gao, King and Lu et al. (2009b), 非参数核估计理论Wang and Phillips (2009a), 部分线性单指标非平稳时间序列模型Dong, Gao and Tjøstheim (2016), 正交级数驱动非平稳时间序列模型的识别性检验Dong and Gao (2018), 非参数可加且具有时间趋势、平稳变量和非平稳变量的回归模型Dong and Linton (2018)和非平稳变系数面板数据模型Dong, Gao and Peng (2020), 仅列举一部分.F
筛分法(sieve method)是计量经济学重要的非参数方法之一, 它和核方法(kernel method) 都是常用的非参数方法, 但较之于核方法, 筛分法在使用上具有高度的灵活性, 在性质上具有全局性而非局部性的特点. 筛分法的名称首先由Grenander (1981)采用, 它使用一个函数系的线性组合在某种数学意义下逼近未知函数, 这种组合构成的空间在文献里就称为线性筛分空间(linear sieve space); 通常, 筛分法使用的函数系包括正交多项式系, 正交三角多项式系, B-样条, 小波和神经网络等等. 筛分法几乎可以在计量经济学所有涉及非参数和半参数的各个领域使用, 比如非参数回归, 极大似然估计, 工具变量法和广义矩方法等等. 关于非参数方法和筛分法请读者参考Rao (1983), Chen and Shen (1998), Gao (2007), Chen (2007), Li and Racine (2007). 本文讨论的筛分法仅限于未知函数的正交级数展开, 严格来讲属于级数估计方法(series estimation), 我们习惯上仍然称之为筛分法.
计量经济学非参数问题中的未知函数通常来自于
一般地, 空间
这里,
在使用筛分法时, 大多数情况下人们都没有明确的线索来确定这两个要素. 就区间而言, 许多现有的文献只考虑有界区间, 比如Newey (1997)中假设8和Ai and Chen (2003, p1803)中假设3.1; 这样的考虑多数情况下是出于简单化的目的. 然而, 这种限制却排除了许多重要的变量, 比如正态随机变量或者服从于指数分布的随机变量; 另外一种被排除的情形是, 当观测值随着样本容量的增大而发散, 非参数函数的定义域就不会包含于任何有界区间. 例如, 假设
为了弥补文献中的这种缺憾, 最近几年研究者们做出了一系列努力. Chen and Christensen (2015)考虑
本文目的有两个: 一是总结筛分法最近发展; 二是回顾非参数非平稳协整模型部分最新结果. 文章在第2节总结了筛分法的数学基础知识, 并指出在使用筛分法时几个关键量和应该回避问题; 文章第3.1节介绍了部分线性单指标非平稳模型的估计和渐近理论, 并使用蒙特卡罗模拟实验验证理论结果; 第3.2节介绍了非平稳非参数时间序列模型识别性检验, 而检验统计量是通过正交级数构造的; 第3.3节介绍了非参数可加非平稳时间序列模型的估计和渐近理论, 而模型的协变量包括三种类型的变量, 即时间变量, 平稳变量和单位根过程, 并将理论结果应用于股市的配对交易策略, 产生较好的结果. 虽然平稳变量的支撑集可能有界也可能无界, 但非平稳变量的支撑集一定是无界的, 所以第3节所有模型都涉及到无界区间上的筛分法. 第4节是结束语.
2 筛分法基础
2.1 $ L^2 $
对于任意的
则空间
这里, 无穷级数的收敛性是在模的意义下成立.
正交多项式系有两个主要来源: 一是Gram-Schmidt正交化方法, 二是微分算子特征函数(即Sturm-Liouville问题). 众所周知, 幂函数系
另一种产生正交多项式系的方法是微分方程求解, 或者说是某种微分算子的特征根与特征函数问题的解. 考虑超几何型微分方程:
其中
引理2.1 对于任意非负整数
具有多项式
这里,
人们通常会额外的要求密度函数
其中
2.2 常见的$ L^2 $
例2.1 空间
其Rodrigues公式为:
正交性为:
和生成函数:
勒让德多项式系满足有界性:
例2.2 空间
且有递推公式:
其正交性为:
例2.3 空间
生成函数为:
其正交性为:
且满足递推公式:
例2.4 空间
生成函数为:
正交性为:
它满足递推公式:
例2.5 空间
其中
这一点对于计量模型估计量的极限理论是非常方便的.
例2.6 空间
另外,
而正交性为
例2.7 空间
则
例2.8 以下是两类常用的三角函数正交系: 1)傅里叶正交系. 令
2.3 级数估计的几个问题
设
这意味着
当
当
当
对于
级数估计的另一类重要问题是正交级数展开(1)的收敛性和收敛速度, 即, 除了按模收敛这个无穷级数是逐点收敛吗? 是一致收敛吗? 如果收敛, 其速度如何? 这些都是关系到筛分法使用的重要问题.
在
级数估计里是否使用正交函数系也很重要. 可能有些读者认为没有必要在非参数问题里, 比如回归
3 筛分法在无穷区间上的应用
这里讲的筛分法在无穷区间上的应用的主要动机是非平稳时间序列, 这样的变量是发散的, 不会囿于任何紧区间, 所以采用无穷区间上的正交系对非参数函数进行逼近是恰当的.
3.1 部分线性单指标非平稳时间序列模型
非线性非平稳时间序列模型在过去二十年里得到广泛关注和大量研究, 参见Park and Phillips(1999, 2001), Karlsen and Tjøstheim (2001), Karlsen, Mykelbust and Tjøstheim (2007), Wang and Phillips(2009a, 2009b, 2012), Gao, King and Lu et al. (2009a, 2009b), Gao and Phillips (2013), Dong, Gao and Tjøstheim (2016), Dong, Gao and Tjøstheim et al. (2017), Dong and Gao(2018, 2019), Dong and Linton (2018), Wang, Wu and Zhu (2018), Dong, Gao and Peng (2019), Dong, Linton and Peng (2021)等等. 这些理论也被应用于面板数据模型和实证分析, 比如Dong, Gao and Peng (2020)和朱平芳等(2020). 这种问题在理论上和实证上被广泛关注是因为非平稳时间序列大量地存在于经济, 金融和相关领域, 并且非线性非参数模型具有极强的灵活性, 从而得到应用者的青睐.
考虑部分线性单指标模型(partially linear single-index model):
这里
众所周知, 纯粹的非参数模型在变量的维数较大时(
当
而这个模型在
估计步骤和模型假设 因为
取任意正整数
进一步, 记向量
就是
一旦得到
下面我们考虑部分线性单指标模型的估计方法. 由(4), 对于每个
其中
记
同样的,
假设A.1
(a) 设
(b) 令
(c) 存在
(d)
(e) 令
注 矩阵的模
由Skorohod表示定理(Pollard (1984))知, 存在一个母概率空间(a richer probability space), 其中有一个随机向量
由于下面的引理是建立在母概率空间上, 本节的所有理论结果都应该理解为母空间的结果, 这一点我们不再重复.
假设B.1
(a) 设
(b) 取
注 条件(a) 保证了截断误差在随后的极限定理推导中可忽略. 条件(b)虽然对于
单指标模型的渐近理论 我们将使用Wooldridge (1994)的基本方法来推导
其中,
取矩阵
值得注意的是, 因为
因此, 单指标模型可以重写为
如果
下面的定理先给出
定理3.1 令
这里
其中,
此外,
本节的所有证明请参考Dong, Gao and Tjøstheim (2016). Revuz and Yor (2005)是介绍布朗运动局部时过程的经典著作, 读者可以从中了解更多内容. 鉴于
其中
因此,
在坐标系
注意到
推论3.1 在假设A.1和B.1下, 当
这里
注意, 经过标准化原来收敛较慢的速度提高到
定理3.2 在假设A.1和B.1下, 当
可以看到,
因为
这里
推论3.2 在假设A.1和B.1下, 当
并且,
我们下面为插入估计量
定理3.3 在假设A.1和B.1下, 当
因为
部分线性单指标模型的渐近理论 记
其中
为推导模型(2)的极限理论, 我们也需要将坐标系进行旋转. 使用正交矩阵
这里
令
用
由此我们有下述定理.
定理3.4 在假设A.1和B.1下, 当
其中
定理3.4表明在部分线性单指标模型中, 线性部分参数的估计量具有线性模型参数估计量的收敛速度(
定理3.5 在假设A.1和B.1下, 对于由式(6)所定义的(
定理3.6 在假设A.1和B.1下, 定理3.2
蒙特卡罗模拟实验 令
例3.1 考虑单指标模型
我们将计算估计量
这里
Part I. 取
表1 单指标模型的估计偏误和标准差
| Bias | s.d. | ||||||
| n | 400 | 600 | 1000 | 400 | 600 | 1000 | |
| –0.0647 | –0.0519 | –0.0388 | 0.2678 | 0.2507 | 0.2042 | ||
| –0.0832 | –0.0684 | –0.0453 | 0.3461 | 0.3285 | 0.2586 | ||
| 0.0043 | 0.0024 | –0.0016 | 0.1005 | 0.0820 | 0.0679 | ||
| 0.0063 | 0.0066 | 0.0050 | 0.0717 | 0.0659 | 0.0515 | ||
可以看到,
Part II. 令
表2 单指标模型的估计偏误和标准差
| Bias | s.d. | ||||||
| n | 400 | 600 | 1000 | 400 | 600 | 1000 | |
| 0.0866 | 0.0768 | 0.0340 | 0.3803 | 0.3748 | 0.3338 | ||
| 0.0013 | –0.0008 | –0.0006 | 0.1388 | 0.1186 | 0.0898 | ||
| –0.0073 | –0.0061 | –0.0031 | 0.0246 | 0.0237 | 0.0128 | ||
| 0.0011 | –0.0018 | –0.0003 | 0.1186 | 0.1080 | 0.0779 | ||
从报告的结果来看,
然而, 从标准差来看,
例3.2 考虑部分线性单指标模型
表 3报告了所有计算结果. 从报表中看到, 所有估计量的偏误和标准差都随着样本容量的增大而减小;
表3 部分线性单指标模型的估计偏误和标准差
| Bias | s.d. | ||||||
| n | 400 | 600 | 1000 | 400 | 600 | 1000 | |
| –0.0495 | –0.0470 | –0.0324 | 0.2652 | 0.2494 | 0.1991 | ||
| 0.0676 | 0.0645 | 0.0435 | 0.3433 | 0.3340 | 0.2572 | ||
| 0.0038 | 0.0031 | 0.0023 | 0.0934 | 0.0798 | 0.0597 | ||
| –0.0062 | –0.0041 | –0.0019 | 0.0761 | 0.0621 | 0.0475 | ||
| –0.0010 | –0.0002 | 0.0001 | 0.0106 | 0.0068 | 0.0038 | ||
| –0.0007 | 0.0001 | 0.0001 | 0.0118 | 0.0067 | 0.0037 | ||
3.2 非参数内生性协整模型识别性检验
关于本节研究的识别性检验, 相关的文献包括Hong et al. (1995), Gao et al. (2009a, 2009b), Hong and Phillips (2010), Wang and Phillips (2012). 其中, Hong and White (1995)在对立假设下考虑了非参数函数的傅里叶级数逼近和样条逼近; Gao et al. (2009b)提出了一种基于非参数核方法的检验, 所针对的模型的回归变量是单整的, 与误差项独立, 而误差项是一个鞅差过程; Gao et al. (2009a)考虑了非平稳非线性自回归模型的检验, 但是对于误差项的密度函数要求苛刻; Hong and Phillips (2010)在实证问题中检验了协整关系的线性性; 而Wang and Phillips (2012)所考察的非平稳非线性回归模型检验则要求回归函数具有一定的增长速度, 比如多项式和幂函数等.
因此, 文献里的研究存在一个空白, 那就是对于可积函数缺乏识别性检验的研究(Wang and Phillips (2012, p731)); 同时, 文献里的研究都不涉及内生性问题, 这对实证研究非常重要. 所以, 我们的研究旨在对可积非平稳内生性模型提出识别性检验统计量, 并允许两种形式的内生性存在. 通常, 解决内生性需要工具变量, 我们在不需要工具变量情形下证明, 原假设下的统计量具有已知的分布, 对立假设下统计量则发散.
注意到, Wang and Phillips (2016)将Dong et al. (2017)的工作论文(2014年)提出的基于核估计方法的统计量扩展到基于内生性的模型. 然而正如Dong et al. (2017)所指出, 这种统计量的表现取决于一个任意选择的权函数. 相反, 我们提出的统计量非常简单且容易使用; 我们的统计量可以识别任意"微小"的局部偏离, 这里"微小"偏离是指趋于零的可积函数, 具体要求见假设C.2.
考虑非参数协整模型:
我们要检验下列假设:
其中
为了拓宽研究范围, 我们允许模型(30)具有两种类型的内生性: 类型(i), 线性过程
在原假设下
模型假设 设
令
假设A.2
(a) 设
(b) 假设
(ⅰ) 对于所有
(ⅱ) 对于所有
(ⅲ) 对于所有
(ⅳ) 对所有
(c) 误差项序列
(ⅰ)
(ⅱ)
这个假设给出了模型(30)的协变量和均衡误差的结构, 它们均以
注意,
当
这里
由第二节知, 厄尔米特函数
假设B.2
(a) 令
(b) 在
(c) 假设
注 条件(a)对于截断参数
条件(b)对收敛
注意到Chen, Gao and Li (2011)研究了在对立假设
条件(c)是一组对原假设下回归函数的要求, 这在类似情形下的文献里经常遇到, 见Gao, Wang and Yin (2011)假设2.4和Wang and Phillips (2012)假设4. 容易看到下列函数类满足要求: 1)
假设C.2 令
(a)
(b) 当
注 条件(a)排除掉零函数
识别性检验: 可积情况 回忆第二节内容, 若
模型(30)在原假设
因此,
因为矩阵
如下面式(40)所讨论, 这种剔除
类似地, 我们构造
注意到
进一步由基函数的正交性可简化为:
这里
显然,
将
如果
得到相合检验统计量. 在非平稳情形下, 我们将证明
其中
定理3.7 假设A.2和B.2成立. 在原假设
其中
定理3.8 假设A.2
本节的所有证明请参考Dong and Gao (2018). 定理3.7给出了检验统计量的极限分布. 定理3.8表明检验统计量针对局部对立假设序列具有非凡功效, 因为在
假设A.2可以用来估计线性过程
注意,
和
作为
引理3.1 定义
定理3.9 当
这里
统计量
识别性检验: 不可积情况 我们把限制条件
给定观测值
其中, 对于任意
为了利用统计量
注意,
这里
虽然
在陈述
假设B*.2
(a) 设
(b) 在原假设(49)下, 存在
(c) 假定
假设B*.2和B.2存在两点区别. 首先,
另一点区别是函数空间. 现在
定理3.10 设A.2和B*.2成立. 在
这里
设A.2, B*.2和C.2成立. 在
同样的, 如果用引理3.1所定义的
注 式(52)结果与式(41)的结果相类似, 只是要注意
蒙特卡罗实验 我们将通过蒙特卡罗模拟实验考察检验统计量
(Ⅰ) 假定
(Ⅱ) 假定
假设里所有的常数随后将会给出. 在第一种生成机制里, 如果
Bootstrap模拟程序: 我们采用bootstrap程序来生成临界值
Step 1 令
(a) 对于机制(I), 采用通常的块bootstrap方法生成
令
(b) 对于机制(II), 用回归bootstrap方法生成
Step 2 用
Step 3 重复以上步骤
Step 4 定义检验水平和功效函数(the size and power functions) 为:
在实验中样本容量分别取
例3.3 本例考察统计量
在机制(I)下, 原假设
在机制(II)下, 原假设
表4 检验水平: m(x)=10 exp(-θ0x2), θ0=1
| n | 检验水平1% | 检验水平10% | ||||||
| κ= | 1/5 | 1/4.5 | 1/4 | 1/5 | 1/4.5 | 1/4 | ||
| 200 | 0.0160 | 0.0126 | 0.0110 | 0.1222 | 0.1162 | 0.1090 | ||
| 500 | 0.0112 | 0.0140 | 0.0120 | 0.1162 | 0.1156 | 0.1046 | ||
| 1200 | 0.0110 | 0.0120 | 0.0106 | 0.1006 | 0.1002 | 0.0918 | ||
| 200 | 0.0162 | 0.0130 | 0.0140 | 0.1236 | 0.1176 | 0.1172 | ||
| 500 | 0.0136 | 0.0130 | 0.0130 | 0.1122 | 0.1052 | 0.1080 | ||
| 1200 | 0.0110 | 0.0098 | 0.0094 | 0.1030 | 0.1050 | 0.1010 | ||
注:
表5
检验功效:
| n | 检验水平1% | 检验水平10% | ||||||
| κ= | 1/5 | 1/4.5 | 1/4 | 1/5 | 1/4.5 | 1/4 | ||
| 200 | 0.7810 | 0.7906 | 0.8016 | 0.9040 | 0.9070 | 0.9126 | ||
| 500 | 0.8196 | 0.8300 | 0.8410 | 0.9156 | 0.9176 | 0.9210 | ||
| 1200 | 0.8544 | 0.8580 | 0.8660 | 0.9328 | 0.9320 | 0.9344 | ||
| 200 | 0.7840 | 0.7956 | 0.8070 | 0.9030 | 0.9047 | 0.9092 | ||
| 500 | 0.8112 | 0.8252 | 0.8326 | 0.9150 | 0.9170 | 0.9220 | ||
| 1200 | 0.8528 | 0.8588 | 0.8694 | 0.9318 | 0.9330 | 0.9380 | ||
注:
表6
检验水平:
| n | 检验水平1% | 检验水平10% | ||||||
| κ= | 1/5 | 1/4.5 | 1/4 | 1/5 | 1/4.5 | 1/4 | ||
| 200 | 0.0146 | 0.0136 | 0.0130 | 0.1092 | 0.1052 | 0.1052 | ||
| 500 | 0.0124 | 0.0116 | 0.0118 | 0.0958 | 0.0956 | 0.0958 | ||
| 1200 | 0.0110 | 0.0104 | 0.0104 | 0.1022 | 0.1004 | 0.1008 | ||
| 200 | 0.0094 | 0.0090 | 0.0080 | 0.1040 | 0.1058 | 0.1024 | ||
| 500 | 0.0114 | 0.0102 | 0.0082 | 0.0950 | 0.1012 | 0.0980 | ||
| 1200 | 0.0102 | 0.0098 | 0.0114 | 0.0988 | 0.0992 | 0.0984 | ||
注:
表7
检验功效:
| n | 检验水平1% | 检验水平10% | ||||||
| κ= | 1/5 | 1/4.5 | 1/4 | 1/5 | 1/4.5 | 1/4 | ||
| 200 | 0.9968 | 0.9974 | 0.9978 | 0.9980 | 0.9988 | 0.9990 | ||
| 500 | 0.9972 | 0.9972 | 0.9974 | 0.9984 | 0.9992 | 0.9994 | ||
| 1200 | 0.9978 | 0.9976 | 0.9986 | 0.9990 | 0.9990 | 0.9996 | ||
| 200 | 0.9846 | 0.9856 | 0.9858 | 0.9954 | 0.9964 | 0.9958 | ||
| 500 | 0.9860 | 0.9868 | 0.9870 | 0.9956 | 0.9958 | 0.9962 | ||
| 1200 | 0.9864 | 0.9860 | 0.9872 | 0.9986 | 0.9968 | 0.9968 | ||
注:
例3.4 为了考察统计量
在机制(I)下, 原假设
在机制(II)下, 原假设
表8
检验水平:
| n | 检验水平1% | 检验水平10% | ||||||
| κ= | 1/5 | 1/4.5 | 1/4 | 1/5 | 1/4.5 | 1/4 | ||
| 200 | 0.0068 | 0.0074 | 0.0070 | 0.0824 | 0.0868 | 0.0854 | ||
| 500 | 0.0104 | 0.0100 | 0.0094 | 0.0908 | 0.0994 | 0.0920 | ||
| 1200 | 0.0100 | 0.0104 | 0.0102 | 0.0994 | 0.0990 | 0.0988 | ||
| 200 | 0.0040 | 0.0044 | 0.0044 | 0.0814 | 0.0818 | 0.0844 | ||
| 500 | 0.0084 | 0.0080 | 0.0094 | 0.0898 | 0.0918 | 0.0954 | ||
| 1200 | 0.0098 | 0.0106 | 0.0112 | 0.1060 | 0.1046 | 0.0984 | ||
注:
表9
检验功效:
| n | 检验水平1% | 检验水平10% | ||||||
| κ= | 1/5 | 1/4.5 | 1/4 | 1/5 | 1/4.5 | 1/4 | ||
| 200 | 0.9174 | 0.9294 | 0.9386 | 0.9562 | 0.9632 | 0.9686 | ||
| 500 | 0.9270 | 0.9350 | 0.9496 | 0.9590 | 0.9660 | 0.9730 | ||
| 1200 | 0.9474 | 0.9520 | 0.9638 | 0.9756 | 0.9776 | 0.9824 | ||
| 200 | 0.9050 | 0.9184 | 0.9324 | 0.9496 | 0.9564 | 0.9626 | ||
| 500 | 0.9280 | 0.9388 | 0.9536 | 0.9630 | 0.9694 | 0.9736 | ||
| 1200 | 0.9526 | 0.9582 | 0.9650 | 0.9758 | 0.9788 | 0.9840 | ||
注:
表10
检验水平:
| n | 检验水平1% | 检验水平10% | ||||||
| κ= | 1/5 | 1/4.5 | 1/4 | 1/5 | 1/4.5 | 1/4 | ||
| 200 | 0.0058 | 0.0054 | 0.0050 | 0.0968 | 0.0900 | 0.0920 | ||
| 500 | 0.0068 | 0.0070 | 0.0060 | 0.0944 | 0.0924 | 0.0972 | ||
| 1200 | 0.0104 | 0.0082 | 0.0104 | 0.0980 | 0.0926 | 0.0986 | ||
| 200 | 0.0060 | 0.0052 | 0.0054 | 0.0920 | 0.0872 | 0.0868 | ||
| 500 | 0.0070 | 0.0074 | 0.0076 | 0.1062 | 0.0950 | 0.0940 | ||
| 1200 | 0.0086 | 0.0078 | 0.0096 | 0.1004 | 0.0970 | 0.0990 | ||
注:
表11
检验功效:
| n | 检验水平1% | 检验水平10% | ||||||
| κ= | 1/5 | 1/4.5 | 1/4 | 1/5 | 1/4.5 | 1/4 | ||
| 200 | 0.9978 | 0.9984 | 0.9988 | 0.9982 | 0.9988 | 0.9990 | ||
| 500 | 0.9988 | 0.9990 | 0.9992 | 0.9992 | 0.9990 | 0.9996 | ||
| 1200 | 0.9990 | 0.9988 | 0.9990 | 0.9992 | 0.9992 | 0.9996 | ||
| 200 | 0.7478 | 0.7934 | 0.8172 | 0.8234 | 0.8960 | 0.9014 | ||
| 500 | 0.8174 | 0.8260 | 0.8474 | 0.8778 | 0.9052 | 0.9182 | ||
| 1200 | 0.8632 | 0.8844 | 0.8928 | 0.9114 | 0.9418 | 0.9416 | ||
注:
3.3 非参数可加非平稳模型
就时间序列而言, 有三种变量在经济、金融和相关领域随处可见, 它们是非随机时间趋势、平稳变量和非平稳变量. 比如, 总消费、可支配性收入和股票价格均为非平稳变量, 而利率和股票交易量常常认为是平稳变量或者具有微弱趋势的局部平稳变量. 因此, 从实用的角度来看, 我们有必要研究这种回归模型, 它们的回归变量涵盖这三种类型的变量.
Grenander and Rosenblatt (1957)是经典的时间趋势参数模型, 而Phillips(2007, 2010)进行了后续研究. 文献里有相当多的文章研究非平稳非参数回归模型. Karlsen, Mykelbust and Tjøstheim (2007)研究非参数回归, 其标量协变量是一个马尔可夫链. Schienle (2008)研究非参数可加模型, 其协变量为哈里斯常返(Harris recurrent) 时间序列并得到核光滑回溯估计量(kernel smooth backfitting estimators)的极限理论. Wang and Phillips (2009a)考虑了非参数单位根回归的核估计. Phillips, Li and Gao (2017)考虑了函数型系数模型, 其协变量为单位根过程而函数型系数则以时间趋势为变量. Wang (2015)是一部优秀的著作, 回顾了关于非平稳时间序列的极限理论.
就我们所知, 很少有文章研究涵盖三种变量的非参数模型. 在Chang, Park and Phillips (2001)中, 虽然三种变量都包含在回归方程里, 但它研究的是非线性参数模型, 即所有的函数都是已知的. 除此之外, 有些文章研究的模型包含了以上提到的三种变量里的两种, 比如Park and Hahn (1999), Xiao (2009), Cai, Li and Park (2009), Li, Phillips and Gao (2016).
我们在这里考虑模型:
其中
我们将对所有未知函数采用级数估计法估计; 可以说, 相比于核方法所需要的回溯技术("backfitting technique", 见Mammen, Linton and Nielsen (1999)), 级数估计对于可加模型是非常方便的(Andrews and Whang (1990)). 确实, 级数估计方法通过最小二乘估计可以得到显式解, 有利于渐近分析. 相反, 回溯方法则需要两步才能得到估计量. 参见Vogt (2012).
模型(54)最重要的特点是解释变量种类的多样性, 从而其应用范围非常广泛. 但是, 它在极限理论上也带来巨大的挑战. 我们的发现包括: 1) 经过适当的标准化,
模型假设和估计 我们先给出单整回归变量
假设A.3
(a) 设
(b) 令
(c) 对于
假设A.3里关于单位根序列的假设是文献里常见的条件, 参见Park and Phillips (1999, 2001), Dong, Gao and Tjøstheim (2016). 独立同分布序列
注意, 由
假设B.3
(a) 假定
(b) 存在定义于支撑集
(c) 存在信息流序列
条件(a)考虑了两种情况
条件(b)是关于支撑集
条件(c)是在文献里广为采用的鞅差序列, 参见Park and Phillips (1999, 2001), Gao and Phillips (2013). 但是, 条件(c) 允许异方差存在, 而异方差函数依赖于时间变量
估计程序 我们采用正交级数逼近和最小二乘法来估计所有未知函数, 根据这些函数的特点和在回归方程里所起的作用, 它们属于不同的函数空间.
首先, 假设
其次, 假设
最后, 因为
取正整数
记
要把方程组(58)写成矩阵形式, 令
它是
那么由最小二乘法可得
对于任意
其中
这里0是零列向量, 在不同的行维数不同.
渐近理论 在介绍极限理论之前我们需要下面的假设.
假设C.3
(a) 设函数
(b) 对于
因为我们不仅需要正交级数的收敛性还需要一定的收敛速度, 所以这个假设要求未知函数具有一定的光滑性. 至于
假设D.3 所有
(a) 如果B.3.(b) (i)成立, 1)
(b) 假设当
这里D.3的条件对截断参数
此外, 条件2)和4)是针对三个
给定假设C.3里的光滑性, 条件D.3.(b)要求导数的阶足够高, 使得余项(
记对角
在同方差情形下,
定理3.11 设
其中
矩阵
在同方差情形
因此, 我们可以将
这些结果与现有文献均有可比性. 注意到关于
更重要的是, 我们可以为
推论3.3 假设A.3
确实, 如果
如果要做统计推断, 那么未知函数
图1
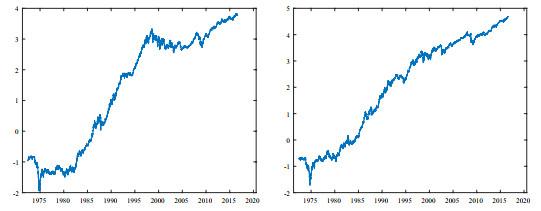
图2
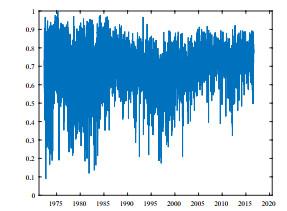
为了验证
图3
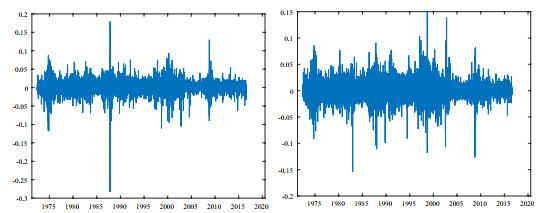
我们将通过下列模型来考察
因为函数
在实证中级数估计的一个关键问题是确定截断参数, 只有当它们确定后, 估计程序才能够进行. 然而, 截断参数的选择并没有理论可循, 尤其是在模型里既包括平稳过程又包括单整过程的情形. 因为预测能力是金融模型的重要特征, 我们将以预测能力为标准来决定截断参数.
模型的预测能力就是所谓样本外均方误差(out-of-sample mse). 对于给定的
在此实证分析中, 取
表12 模型(65)样本外均方误差
| k3 | k1(=k2) | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| 1 | 0.0146 | 0.0515 | 0.0241 | 0.0364 | 0.0358 | 0.0251 | 0.0227 |
| 2 | 0.0752 | 0.0392 | 0.0190 | 0.0251 | 0.0454 | 0.0378 | 0.0342 |
| 3 | 0.0529 | 0.0316 | 0.0150 | 0.0191 | 0.0380 | 0.0332 | 0.0314 |
| 4 | 0.0329 | 0.0293 | 0.0197 | 0.0225 | 0.0367 | 0.0330 | 0.0318 |
| 5 | 0.0315 | 0.0290 | 0.0196 | 0.0224 | 0.0407 | 0.0383 | 0.0368 |
| 6 | 0.0260 | 0.0299 | 0.0226 | 0.0248 | 0.0388 | 0.0356 | 0.0338 |
从表中可以看到
这里
图4
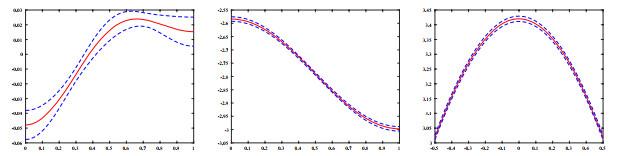
配对交易策略. 在模型估计的基础上, 我们进一步考虑它在配对交易策略中的表现如何. 配对交易策略在华尔街已经有三十多年的历史了, 属于所有权"统计套利"工具, 被对冲基金和投资银行所采用. 配对策略充分利用两支相关股票的协整关系, 当二者过度分离或者靠近时做多头或者空头, 而当它们的价格趋于正常时则平仓. 参见Gatev, Goetzmann and Rouwenhorst (2006). 然而, 在相关的文献里协整关系都是采用线性方程来描述, 与之形成鲜明对照的是, 我们将采用非参数非线性协整模型框架下的配对交易策略.
取正整数
交易策略如下. 从
从数学上讲, 当
那么, 交易期的总利润为
取
表13 可口可乐和百事可乐配对交易
| 非线性协整 | 线性协整 | |||||||
| α | L(α/2) | Profit | L(α/2) | Profit | ||||
| n0=7000 | 0.01 | 0.3511 | –1.2710 | 0.0227 | 0.5678 | –0.4937 | 0 | |
| 0.05 | 0.1130 | –1.2025 | 0.6525 | 0.4631 | –0.4324 | 0.0767 | ||
| n0=7500 | 0.01 | 0.3450 | –1.2669 | 0.0227 | 0.5680 | –0.4874 | 0 | |
| 0.05 | 0.1012 | –1.1963 | 0.8162 | 0.4614 | –0.4236 | 0.1389 | ||
| n0=8000 | 0.01 | 0.3401 | –1.2647 | 0.0227 | 0.5681 | –0.4828 | 0 | |
| 0.05 | 0.0806 | –1.1913 | 0.9117 | 0.4580 | –0.4167 | 0.1931 | ||
| n0=8500 | 0.01 | 0.3318 | –1.2561 | 0.0145 | 0.5646 | –0.4780 | 0 | |
| 0.05 | 0.0704 | –1.1963 | 0.7515 | 0.4562 | –0.4122 | 0.5708 | ||
| n0=9000 | 0.01 | 0.3234 | –1.2622 | 0 | 0.5635 | –0.4734 | 0 | |
| 0.05 | 0.0580 | –1.2059 | 0 | 0.4547 | –0.4153 | 0 | ||
可以看到, 多数结果对于历史数据的长度(即
4 结论
在这篇文章里我们总结和回顾了最近几年计量经济学筛分法的发展和成果, 特别是当研究的问题里变量的取值属于无界区间时传统的筛分法就必须扩展到无限区间上. 一个重要的例子就是非平稳时间序列(比如单位根过程), 因其二阶矩是发散的, 它不会囿于任何有界紧区间, 研究者必须考虑无穷区间上的筛分法. 文章的第三节讨论的三类模型均包括非平稳时间序列, 其非参数估计量均出自筛分法. 当然, 读者从文章里还可以看到所综述的文章在计量经济学其他方面的突破, 在此不一一列举, 以免偏离本文的宗旨. 值得一提的是, 虽然文章里谈到的都是时间序列, 本文研究的方法也可以应用到其他类型的数据, 比如面板数据, 只要它具有这里描述的特征即可.
参考文献
汇率预测的"米斯和罗戈夫之谜"破解——来自非参数方法的回答,
[J].
"The Meese and Rogoff Puzzle" in Exchange Rate Forecasting-Answers from Nonparametric Method
[J].
Efficient Estimation of Models with Conditional Moment Restrictions Containing Unknown Functions
[J].
Asymptotic Normality of Series Estimators for Nonparametric and Semiparametric Regression Models
[J].
Additive Interaction Regression Models: Circumvention of the Curse of Dimensionality
[J].
Some New Asymptotic Theory for Least Squares Series: Pointwise and Uniform Results
[J].
Functional-coefficient Cointegration Models for Nonstationary Time Series Data
[J].
Generalized Partially Linear Single-index Models
[J].
Nonlinear Econometric Models with Cointegrated and Deterministically Trending Regressors
[J].
Estimation in Semiparametric Time Series Regression
[J].
Optimal Uniform Convergence Rates and Asymptotic Normality for Series Estimators under Weak Dependence and Weak Conditions
[J].
Sieve Extremum Estimates for Weakly Dependent Data
[J].
Specification Testing Driven by Orthogonal Series for Nonlinear Cointegration with Endogeneity
[J].
Expansion and Estimation of Levy Process Functionals in Non-linear and Nonstationary Time Series Regression
[J].
Semiparametric Single-index Panel Data Models with Cross-sectional Dependence
[J].
Series Estimation for Single-index Models under Constraints
[J].
Varying-coefficient Panel Data Models with Nonstationarity and Partially Observed Factor Structure
[J].
Estimation for Single-index and Partially Linear Single-index Integrated Models
[J].
Specification Testing for Nonlinear Multivariate Cointegrating Regressions
[J].
Additive Nonparametric Models with Time Variable and both Stationary and Nonstationary Regressors
[J].
A Weighted Sieve Estimator for Nonparametric Time Series Models with Nonstationary Variables
[J].
Nonparametric Specification Testing for Nonlinear Time Series with Nonstationarity
[J].
Specification Testing in Nonlinear and Nonstationary Time Series Autoregression
[J].
Semiparametric Estimation in Triangular System Equations with Nonstationarity
[J].
Model Specification Tests in Nonparametric Stochastic Regression Models
[J].
Specification Testing in Nonlinear Time Series with Long-range Dependence
[J].
Pairs Trading: Performance of a Relative-value Arbitrage Rule
[J].
On Blocking Rules for the Bootstrap with Dependent Data
[J].
Optimal Smoothing in Single-index Models
[J].
Testing Linearity of Cointegriting Relations with an Application to Purchasing Power Parity
[J].
Consistent Specification Testing via Nonparametric Series Regression
[J].
An Adaptive Rate-optimal Test of a Parametric Mean-regression Model Against a Nonparametric Alternative
[J].
Gaussian Pseudo-maximum Likelihood Estimation of Fractional Time Series Models
[J].
Nonparametric Estimation in a Nonlinear Cointegration Type Model
[J].
Nonparametric Estimation in Null Recurrent Time Series
[J].
Christoffel Functions, Orthogonal Polynomails, and Nevai's Conjecture for Freud Weights
[J].
Uniform Consistency of Nonstationary Kernel-weighted Sample Covariance for Nonparametric Regressions
[J].
A Simple Consistent Bootstrap Test for a Parametric Regression Functional Form
[J].
Estimation and Testing for Partially Linear Single-index Models
[J].
A New Approach to Universality Limits Involving Orthogonal Polynomials
[J].
Doubly Robust and Efficient Estimators for Heteroscedastic Partially Single-index Models Allowing High Dimension Covariates
[J].
The Existence and Asymptotic Properties of a Backfitting Projection Algorithm under Weak Conditions
[J].
Weak Convergence of Multivariate Fractional Processes
[J].
Convergence Rates and Asymptotic Normality for Series Estimators
[J].
Cointegrating Regressions with Time Varying Coefficients
[J].
Asymptotics for Nonlinear Transformations of Integrated Time Series
[J].
Nonstationary Binary Choice
[J].
Nonlinear Regression with Integreted Time Series
[J].
Regression with Slowly Varying Regressors and Nonlinear Treads
[J].
Estimating Smooth Structure Change in Cointegration Models
[J].
Asymptotics for Linear Processes
[J].
Profile Likelihood and Conditionally Parametric Models
[J].
Optimal Global Rates of Convergence for Nonparametric Regression
[J].
Additive Regression and other Nonparametric Models
[J].
Nonparametric Regression for Locally Stationary Time Series
[J].
Estimation for a Partial-linear Single-index Model
[J].
Asymptotic Theory for Local Time Density Estimation and Nonparametric Cointegreting Regression
[J].
Structure Nonparametric Cointegrating Regression
[J].
A specification Test for Nonlinear Nonstationary Models
[J].
Nonparametric Cointegrating Regression with Endogeneity and Long Memory
[J].
Model Checks for Nonlinear Cointegrating Regression
[J].
Using Least Squares to Approximate Unknown Regression Functions
[J].
Single-index Quantile Regression
[J].
On Single-index Coefficient Regression Models
[J].
On Extended Partially Linear Single-index Models
[J].
An Adaptive Estimation of Dimension Reduction
[J].
Functional-coefficient Cointegration Models
[J].
Penalized Spline Estimation for Partially Linear Single-index Models
[J].
Empirical Likelihood Confidence Regions in a Partially Linear Single-index Model
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}