


1 引言
为了评估或评价培训计划和实施政治或社会或者经济政策或事件对结果的影响, 人们需要估计其处置效应treatment effect (或者处理效应), 这在经济、金融等许多应用领域都引起了极大的兴趣和关注, 在估计处置效应的过程中, 往往需要高级计量经济学知识或统计分析工具.估计处置效应的难度在于没有处置的单元的结果未被直接观测到, 通常称为反事实(counterfactual).为了克服这一困难, 已有文献中提出了许多方法, 如回归调整、匹配、逆概率(倾向得分函数, propensity score function)加权、双重差分(difference-in-differences, DiD)、断点回归方法等等, 来估计平均处置效应(ATE)和分位数处置效应(QTE).然而, 上述方法大多依赖于估计倾向得分函数, 比如, 关于横截面数据可参考Imbens and Wooldridge (2009)的文章, 时间序列数据可参考Liu, Cai and Fang et al. (2020)的综述文章, QTE方面可参考Tang (2020)的综述文献, 更多细节的内容可见参考书Cerulli (2015).
在上述的解决处置效应的计量经济学方法中, 在应用中, 比较流行的方法是经典DiD方法, 被要求有两个时间段(处置前后)和两组(处置组和对照组)的情况下.并且如果平行趋势假设成立, 那么处置组的ATE可以简单地通过处置组的平均结果随时间的变化和对照组的平均结果随时间的变化的差异来估计.众所周知, DiD类型方法避免估计倾向得分函数, 以避免倾向得分函数可能的错误假设.因此, 对于大面板数据, Hsiao, Ching and Wan (2012) (以下简称为HCW)把经典的DiD方法做了创造性拓展, 可以用来处理大面板数据, 称为HCW方法.
事实上, HCW提出了一个基于因子模型来估计面板数据的平均处置效应.与面板数据的经典DiD方法不同, HCW考虑了具有多个单元和多个时间段的面板数据, 其中处置发生在特定时间和之后.他们的重点是通过将其他单位作为对照组来观测特定单位的处置效应.如果HCW的面板数据的横截面截面和时间序列的维度较大, 可以采用Bai and Ng (2002), Pesaran (2006), Bai (2009)等方法来估计影响因子.然而, 在许多应用中, 研究者经常遇到维度不大的情况.针对这一问题, HCW提出了一种不考虑因子的反事实结果估计方法.在某些简单假设条件下, HCW证明了利用普通最小二乘回归仍然可以得到其估计量, 从而使计算变得简单.此外, 正如Li and Bell (2017)所指出的, HCW中的方法优点之一是不需要假设没有样本选择效应.换句话说, 它绕过了虚拟处置和结果之间的相关性问题.此外, 它不要求处置单位和控制单位在没有处置的时间遵循平行路径.
近年来, 研究人员从理论和实证的角度对HCW的研究方法进行了广泛的拓展和应用.例如, 首先, 通过应用HCW的方法, Chen, Han and Li et al. (2013)构建现货市场波动率的反事实以及主要基于中国与国际股票市场的横截面相关性, 研究了引入沪深300 (CSI300)1指数期货交易对中国股市现货价格波动率(VIX)的影响.其次, Bai, Li and Ouyang (2014)将HCW的方法扩展到相关的时间系列是非平稳单位根过程的情况, 然后, 探讨房产税对房价的影响, 利用2011年1月开始在上海和重庆进行的房产税政策试验, 并利用其他省市的房价, 采用HCW的方法估计上海和重庆在不征收房产税的情况下的假设房价.第三, Ouyang and Peng (2015)放宽了HCW中的线性回归函数假设, 允许存在非参数回归函数, 并将HCW模型推广到半参数设置, 并以此方法研究2008年中国的经济刺激方案.第四, Du and Zhang (2015)建议使用"多个剔除交叉验证"(leave-many-out cross validation)准则代替HCW中的Akaike信息准则(AIC)来选择最优控制单元, 并将其应用于对中国的购房限制、房产税和房价的反事实分析.此外, Ke, Chen and Hong et al. (2017)利用1990年到2013年中国地级市数据, 通过在没有高铁项目的情况下利用选定的非高铁城市的结果, 构建高铁城市人均实际GDP的假设反事实, 评估了高铁项目对目标城市节点(高铁城市)经济增长的影响.此外, Li and Bell (2017)认为HCW的方法可以在限制性较小的假设下仍然是有效, 实际上, Li and Bell (2017)去掉了HCW中施加的一些假设, 然后导出了HCW平均处置效应估计量的渐近性质.另外, Li and Bell (2017)将最小绝对收缩和选择算子(least absolute shjrinkage and selection operator, LASSO)方法引入HCW的方法中使得控制元选择在横截面尺寸很大的情况下更加有效, 而Carvalho, Masini and Medeiros (2018)证明了LASSO估计量是相合的并且渐近正态分布的.更重要的是, Carvalho et al. (2018)将HCW的方法推广为一种灵活且易于实施的方法, 称为ArCo, 用于在没有对照组的情况下, 估计干预对单个处置单元的因果效应, 这与文献中之前的建议一致, 此外, 他们还考虑了多种干预措施和受污染效应的测试.最后, Carvalho et al. (2018)应用他们的模型评估了2007年巴西实施的反逃税计划对通货膨胀和其他宏观经济变量(比如:经济增长、零售和信贷)的影响.
1沪深300指数是一个市值加权的股市指数, 旨在复制在上海和深圳交易所交易的前300只股票的表现.
最近, 为了利用面板数据或纵向数据(longitudinal data)进行因果推断, 以捕捉异质处置效应, 双因素线性固定效应回归(two-way linear fixed effect, 记为2FE)已成为面板数据估计因果效应的默认方法.使用2FE估计量的主要目的是同时调整未观测到的特定单位和/或特定群体和/或特定时间的混杂因素.事实上, 根据De Chaisemartin and D'Haultfoeuille (2020)的一项调查, 在2010年至2012年期间, 顶尖经济学杂志《美国经济评论》发表的所有实证文章中, 有19%使用了双因素固定效应回归来估计处置对结果的影响.例如, 为了估计ATE, Imai and Kim (2019, 2020)提出了与2FE模型匹配的方法, 以捕获未观测到的特定单位和特定时间的混杂因素, 而De Chaisemartin and D'Haultfoeuille (2020)提出了另外一种新的估计方法, 以适应未观测到的特定群体和特定时间的混杂因素.最后, Sun and Abraham (2020)提出了一种替代方法来估计一个有趣处置的动态效应, 而不是包括处置的领先和滞后的双向固定效应回归, 当平行趋势假设只有在观测到的协变量的条件作用下才可能成立时, Callaway and Sant'Anna (2020)表明, 即使观测到的特征的差异导致组间的非平行结果动态变化, 在交错DiD设置中也确定了一系列因果效应参数.根据他们的鉴定结果, 他们提出了不同的聚类方案, 可以用来突出不同维度的处置效应异质性, 并总结参与处置的整体效应.
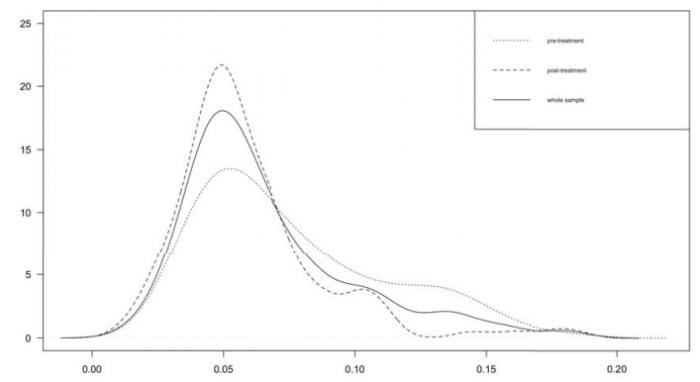
尽管ATE方法在应用很受欢迎, 但当潜在结果的真实分布是不对称或异质性或厚尾时, ATE可能不能很好地代表政策的效果.例如, 让我们观察Chen et al. (2013)所考虑的沪深300指数现货价格波动率在2002年1月至2020年10月的分布估计, 如图 1所示, 从图 1可以清楚地看到三个样本的密度分布:处置前(点线)、处置后(虚线)和整个样本(实线)的分布是不对称的, 并且是严重向右倾斜的.因此, ATE可能不适用于这个应用问题来刻画政策效应.相反, 我们需要考虑处置效应的分布影响.在文献中, 分位数处置效应(QTE)可以用来识别政策在对应于观测结果和反事实结果的整个分布的任何分位数上的效应.
图1
然而, 关于用面板数据估计QTE的文献非常有限.大概, 最近的文献包括Callaway, Li and Oka (2018)以及Callaway and Li (2019), 他们考虑在Copula不变性的假设下(见后面的假设Q2), 在固定时间段(有限面板)的DiD设置下使用面板数据估计QTE (见后面的假设Q2), 以及Cai, Fang and Lin et al. (2021)的文章, 该文将HCW的方法推广到面板数据的QTE设置, 从而对大面板数据的处置效果进行了综合刻画和考察.估计反事实的分位数的处置单位, 不同于HCW的方法及其它的扩展, Cai et al. (2021)引入了条件累积分布函数(CDF)不变性的假设(见后面的假设Q3), 提出了一个简单的方法来使用条件CDF和无条件的CDF之间的关系.通过这种方法, 可以使用非参数和半参数方法来估计条件CDF.此外, Cai et al. (2021)导出了所提出的QTE估计量的大样本性质, 以及一种基于区块(blockwise) Bootstrap的易于实现的构造置信区间的方法.
最后, 使用QTE面板数据方法, Cai et al. (2021)通过分位数处置效果分析, 研究引入沪深300指数期货交易, 2010年4月16日由中国金融期货交易所正式推出, 是否对会现货市场波动率以及像Huang, Schlag and Shaliastovich et al. (2019)那样的波动率之波动率(volatility-in-volatility, VVIX)2产生影响.引入后, 有人批评引入指数期货交易可能会因过度投机而动摇现货市场, 也有人认为指数期货市场可以提高信息流的速度和质量, 使金融市场更加完善. Cai et al. (2021)的研究有趣发现是, 引入沪深300指数期货交易不仅对中国金融市场的VIX有显著影响, 而且对VVIX也有显著影响.
2波动率之波动率的定义可以在Huang et al. (2019)中找到.
本文的其余部分组织如下.第2节致力于回顾经典的DiD方法及其变体, 如用于估计多个时间段的ATE的双因素固定效应.第3节详细阐述了HCW的方法及其扩展, 第4节讨论了有限面板数据和大型面板数据的QTE估计.第5节是本文的结束语, 同时, 讨论了一些非常有趣而且挑战性极强的未来研究问题, 尤其和机器学习相关的未来研究方向.
2 面板数据的双重差分方法
2.1 两期的双重差分方法
首先, 让我回顾一下经典的DiD方法, 尽管它在计量经济学文献中众所周知, 例如, 见Cerulli (2015).事实上, 经典的DiD需要从一个实验组和一个控制组在两个或两个以上不同时期(比如,
其中系数是用希腊字母
为了估计
其中
值得一提的是, 最近, Henderson and Sperlich (2021)成功地把(2)推广到带有confounder (混杂变量)的非参数DiD情况, 也就是考虑处置效应函数
3DACA, "童年抵美者暂缓遣返"计划, 是由奥巴马于2012年发起, 准许在年幼还没有决定权的时候跟着自己的父母或是一级亲属来到美国的人可以继续待在美国合法的工作跟生活, 不必被强硬地遣返回去自己的国家.但是必须每两年就重新续约一次这个协议
最后, 我深信国内学者对模型(1)有许多实证应用, 通常采用(2)式中的估计方法
2.2 双因素固定效应双重差分方法
近年来, 为了利用面板数据或纵向数据进行因果推断, 捕捉异质和动态的处置效应, 双因素线性固定效应回归已成为一种流行的方法, 用于从面板数据估计因果效应, 以调整未观测到的单位特定和/或群体特定和/或时间特定混杂因素.例如, 参见近期和新兴的关于DiD和/或事件研究中不同处置时间的异质处置效应的文献, 包括但不限于, Imai and Kim (2019, 2020), De Chaisemartin and D'Haultfoeuille (2020), Sun and Abraham (2020), Callaway and Sant'Anna (2020)以及其中的参考文献.实际上, Imai and Kim (2020)考虑了以下双因素线性固定效应回归模型
对于
另外, 在De Chaisemartin and D'Haultfoeuille (2020)的这篇文章中, 假设在同一
其中
最后, Sun and Abraham (2020)提出了一种替代方法来估计随时间变化的动态效应, 而不是包括处置的超前和滞后的双向固定效应回归, 并且当平行趋势假设只有在观测到的协变量的条件下才可能成立时, 而Callaway and Sant'Anna (2020)考虑了识别和估计问题, 并表明在交错DiD设置中识别了一系列因果参数, 即使观测到的特征差异在组间产生了不平行的结果动态变化. Callaway and Sant'Anna (2020)根据识别结果提出了不同的聚类方案, 可用于突出不同维度的处置效应异质性, 总结参与处置的整体效应.关于细节, 读者可以参考上述文章和其中的参考文献. Sun and Abraham (2020)利用他们提出的方法研究了住院治疗的经济后果, 这是美国成年人经济风险的一大来源, 而Callaway and Sant'Anna (2020)通过分析2001年至2007年美国最低工资对青少年就业的影响, 阐述了他们提出的工具的相关性.
在许多使用面板数据或纵向数据的项目评估应用中, 双因素固定效应(2FE)方法通常被使用, 如上两节所述.问题是2FE估计量与经典估计量有什么不同.实际上, 根据上面对两种方法的描述, 人们可能已经看到了它们之间的区别.然而, 即使使用DiD进行估计所需的识别条件比FE更少, 由于前期零处置条件, 使用DiD减少了估计ATE所需的观测次数.当观测量显著减少时, 可以使用DiD方法.然而, 如果观测数量急剧下降, 则需要使用FE估计, 因为FE可能对ATE产生更稳健的估计.关于以上两种方法的更多比较, 读者可以参考Cerulli (2015)的书.最后, 正像Henderson and Sperlich (2021)那样, 把(2)经典DiD方法推广到非参数情况, 是否可以把上述2FE各种方法推广到非参数情景有待我们进一步探讨和研究, 希望年轻学者可以往这个方向去思考.
3 面板数据的HCW方法
3.1 模型和估计方法
本节专门介绍HCW方法及其扩展和应用.为此, 对
由于无法同时观测到
如果在时间
其中
具体来说, 在HCW方法中, 尽管驱动所有横截面单元的一些共同因素对每个横截面单元的影响可能不同, 但可以假设横截面单元之间的相关性是由它们导致的.因此, 根据
4HCW在Li and Bell (2017)的假设HCW3下推导(4), 该假设被Li and Bell (2017)所抛弃.
为估计反事实结果
通过假设数据结构在处置前后保持不变和其他假设, 如HCW中列出的假设1
最后, 对第一个单位的平均处置效果进行估计:
可以通过将处置后观测到的结果和估计的反事实结果之间的差异取平均值来构建:
其中
备注1 我们可以看到, 使用HCW方法的一个进步是避免像Bai and Ng (2002), Pesaran (2006), Bai (2009)中那样估计公共因子
对于(3)中对时间序列
另外, Li and Bell (2017)放宽了HCW中的一些分布假设, 如线性条件均值函数形式假设和HCW中的假设6, 并表明HCW的方法确实适用于更广泛的数据生成过程.然后, Li and Bell (2017)导出了
最近, Fujiki and Hsiao (2015)对HCW的方法进行了进一步扩展, 以理清当观测到的结果受两种处置方法的影响时一种方法对另一种的影响. Fujiki and Hsiao (2015)使用了1995年1月17日发生的Hanshin-Awaji大地震作为研究问题的动机, 提出这个新的方法, 他们的研究发现地震没有持续的影响, 观测到的持续效应是兵库县的结构变化造成的.
3.2 控制元选择
当有大量的控制单元(
其中
4 面板数据的QTE方法
众所周知, 如果潜在结果的分布不太集中于均值或存在结果的异质性, 平均处置效果可能不符合理想方法的描述效果.要把握一种处置效果的全局效应, 自然要研究处置效果的整体分布.在本节中, 我们的重点是估计面板数据的分位数处置效果.
4.1 小面板的QTE模型
对于两期面板数据, Callaway et al. (2018)考虑了一个DiD框架, 在该框架中, 样本中的所有个体在
其中
为了衡量处置效果, Callaway et al. (2018)考虑在给定
其中
假设Q1 (分布DiD)对所有
也就是说, 在给定
假设Q2 (Copula不变性)对每个
也就是说, 在给定
在假设Q1和Q2以及其他一些假设下, Callaway et al. (2018)表明, 感兴趣变量的反事实分布可以从未处置个体的观测结果中识别出来.这意味着, 处置组和未处置组在分布意义上必须相似, 不仅是边缘分布, 而且在某些时期的依赖性.因此假设Q1和Q2在识别中发挥关键作用, 如Callaway et al. (2018)所示.此外, Callaway et al. (2018)提供了
更进一步, Callaway and Li (2019)把上述方法推广到至少有三个观察时间点到面板数据情况(
其中
备注2 对于有限的面板数据, 如何通过使用2FE方法来刻画异质性处置的特征来估计QTE在文献中似乎没有很好地解决.因此, 未来有可能对这一课题进行研究.
4.2 大面板的QTE方法
4.2.1 模型和估计方法
不同于Callaway et al. (2018), Callaway and Li (2019), 假设面板数据是带有协变量
其中
其中
一般来说, 条件CDF
假设Q3 (条件CDF不变性) (i)给定
假设Q3假定处置组和对照组之间存在某种结构不变性, 这确保了给定协变量, 处置组和对照组之间未处置的潜在结果的分布具有可比性.在假设Q3下, 可以通过观测到的对照组数据来估计处置组的反事实条件CDF.这一假设与Rothe (2010)中的非参数结构模型的假设1基本上一致, 同时, 类似于Hsu, Lai and Lieli (2020)中的假设2.3.因此, 可以利用处置前的观测数据估计条件CDF
解上述方程得到
如果有很多控制单元和协变量个数的时候; 即
对于一个很小的常数
且
其中对于任意
最后, 不同于Chen et al. (2013)仅考虑ATE, Cai et al. (2021)运用上述所提出方法, 通过估计QTE来确定引入沪深300指数期货交易对中国股市的VIX及其VVIX可能产生的影响.实证结果表明, 引入沪深300指数期货交易对我国股市VIX及其VVIX均有显著的影响.
备注3 需要注意的是, Cai et al. (2021)仅考虑一个处置, 该假设应该扩展到有多种处置的情况, 如Fujiki and Hsiao (2015)估算ATE的情况.这种扩展似乎有助于评估宏观经济政策的有多个处置的效果, 如Liu et al. (2020)和其他应用.此外, 与Callaway et al. (2018)类似, 人们可能会有兴趣考虑(部分)条件分位数处置效应(CQTE), 比如,
其中
4.2.2 控制元和协变量选择
如果
其中
其中
备注4 首先, 如果面板数据中时间序列是平稳的和
其中
5 结论与未来研究问题探讨
在许多应用领域, 特别是计量经济学, 定量评价经济政策或干预措施的效果是经济研究和政策研究的核心问题之一.从我个人的角度来看, 本文对面板数据(包括有限面板和大型面板)的经济政策评估的最新进展进行了选择性回顾.综上所述, 经济政策评价仍然是一个充满活力和挑战性的研究领域, 值得进一步研究.毫无疑问的是, 在不久的将来这一领域将受到极大的关注.例如, 其重要性和挑战性在于考虑其他方法, 如合成控制方法(synthetic control method, SCM)等; 参见Wan, Xie and Hsiao (2018)通过模拟来估算ATE, 以便比较HCW方法和SCM方法, Cai et al. (2021)的估算大型面板数据的QTE等方法.
随着时间的推移, 经济政策本质上是不同的, 因为同一类型的政策冲击在不同的时期或在不同的经济情景下实施, 相关政策制度的规模是不同的.因此, 本文的部分讨论了通过控制其他策略场景来确定一个策略影响的一些潜在方法.当然, 未来关于时变政策影响能否在这种框架下得到解决的研究是非常有趣的, 也会有一些有趣的应用.除了前面提到的一些开放问题(如上文所述), 用于估算面板数据的ATE和QTE的方法不需要倾向评分函数的说明, 以避免可能的错误假设.另一个避免估计倾向值函数的有趣方法是使用模拟方法来估计反事实的结果, 例如陆昌, 刘详和杨晓光(2021)所提出的方法.此外, 这些方法之间的一些比较(理论和实证)是绝对需要的.
最后, 正如Carvalho et al. (2018), Athey (2019), 洪永淼和汪寿阳(2021), 和萧政(2021)所提到的, 计量经济学和统计结合人工智能, 机器学习(ML)和因果推断在一起进行综合研究, 是一个崭新的研究课题, 以及从ML和统计学或者计量经济学的角度提供见解和理论结果的文献, 如何对使用这些工具来估计面板数据的ATE和QTE的提供了一个很好的参考.实际上, 对于监督性学习, 文献上已经有很多方法, 比如, 正则回归(LASSO, 岭回归), 随机森林, 回归树, 支撑向量机器, 人工神经网络, 矩阵填充(matrix completion and factorization), 深度学习(deep learning), 梯度提升(boosting), 以及模型平均(model averaging techniques)等等, 关于经济学和机器学习之间关系的细节, 参见Athey (2018).比如, Wager and Athey (2018)成功地引进所谓因果森林(causal forest), 是由许多因果树(causal trees)来加权而成, 来刻画不同因果树的各种异质性, 而Carvalho et al. (2018)提出了人工反事实方法(ArCo)来解决高维度面板数据问题.进一步, 这个ArCo方法已经被Masini and Medeiros (2019)推广来处理高维度和非平稳(固定时间趋势或者随机趋势)问题, 以便估计反事实结果.不过, 如何把上述提到的机器学习的方法应用到基于面板数据的ATE和QTE估计问题或者统计推断问题, 建立一套崭新的计量经济学/统计学的方法论和理论体系, 看来不是一件简单的事, 需要国内外学者共同努力去解决.而解决这些问题对年轻学者来说的确是一个挑战, 希望国内学计量经济学或者统计学学者在这个领域能够开创出一片新的研究天地, 为国内学者在这个研究领域树立一个里程碑.
参考文献
大数据、机器学习与统计学:挑战和机遇
[J].
Big Data, Machine Learning and Statistics: Challenges and Opportunities
[J].
大数据时代关于预测的几点思考
[J].
Some Thoughts on Prediction in the Presence of Big Data
[J].
基于反事实模拟的中国股市涨跌停板磁吸效应研究
[J].
Magnet Effect of Price Limits in China's Stock Markets Based on Counterfactual Simulation
[J].
Property Taxes and Home Prices: A Tale of Two Cities
[J].
Panel Data Models with Interactive Fixed Effects
[J].
Determining the Number of Factors in Approximate Factor Models
[J].
Nonparametric Estimation of Conditional VaR and Expected Shortfall
[J].
Quantile Treatment Effects in Difference in Differences Models with Panel Data
[J].
Quantile Treatment Effects in Difference in Differences Models Under Dependence Restrictions and With Only Two Time Periods
[J].
ArCo: An Artificial Counterfactual Approach for High Dimensional Panel Time Series Data
[J].
Does Index Futures Trading Reduce Volatility in the Chinese Stock Market? A Panel Data Evaluation Approach
[J].
Quantile and Probability Curves Without Crossing
[J].
Inference on Counterfactual Distributions
[J].
Two-way Fixed Effects Estimators with Heterogeneous Treatment Effects
[J].
Home Purchase Restriction, Property Tax and Housing Price in China: A Counterfactual Analysis
[J].
An Alternative Test for Conditional Unconfoundedness Using Auxiliary Variables
[J].
Disentangling the Effects of Multiple Treatments—Measuring the Net Economic Impact of the 1995 Great Hanshin-awaji Earthquake
[J].
Approximating Conditional Distribution Functions Using Dimension Reduction
[J].
A Panel Data Approach for Program Evaluation: Measuring the Benefits of Political and Economic Integration of Hong Kong With Mainland China
[J].
Volatility-of-Volatility Risk
[J].
When Should We Use Unit Fixed Effects Regression Models for Causal Inference With Longitudinal Data?
[J].
Recent Developments in the Econometrics of Program Evaluation
[J].
Do China's High-speed-rail Projects Promote Local Economy?—New Evidence From a Panel Data Approach
[J].
Smoothly Clipped Absolute Deviation on High Dimensions
[J].
Regression Quantiles
[J].
Estimation of Average Treatment Effects With Panel Data: Asymptotic Theory and Implementation
[J].
L1-Norm Quantile Regression
[J].
Statistical Analysis and Evaluation of Macroeconomic Policies: A Selective Review
[J].
Estimation and Inference in Large Heterogeneous Panels With a Multifactor Error Structure
[J].
The Treatment Effect Estimation: A Case Study of the 2008 Economic Stimulus Package of China
[J].
Nonparametric Estimation of Distributional Policy Effects
[J].
Some Recent Developments in Modeling Quantile Treatment Effects
[J].
Estimation and Inference of Heterogeneous Treatment Effects Using Random Forests
[J].
Panel Data Approach vs Synthetic Control Method
[J].
Quantile Regression for Analyzing Heterogeneity in Ultra-high Dimension
[J].
Variable Selection in Quantile Regression
[J].
Semismooth Newton Coordinate Descent Algorithm for Elastic-net Penalized Huber Loss Regression and Quantile Regression
[J].

{kind=link}
{kind=link}